Github CI
主要记录与Github工作流相关的笔记。
基于markdown格式的电子书工具:gohugo、mdbook和peach。
基于GitHub+mdBook搭建个人笔记
准备
准备工作如下:
-
安装版本控制工具 Git:
- windows:https://git-scm.com/downloads/win,安装时勾选「Add Git to PATH」,方便命令行调用。
- Mac:https://git-scm.com/download/mac 或
brew install git
验证安装:打开终端输入
git --version,显示版本号即成功。 -
安装mdbook并配置环境变量:
- 访问 mdBook Releases 页面,下载对应系统的压缩包(如 Windows 选
mdbook-v0.4.52-x86_64-pc-windows-msvc.zip) - 解压压缩包,将mdbook.exe(Windows)或mdbook(Mac/Linux)放到系统环境变量目录:
- Windows:复制到
C:\Windows\System32或自定义目录并添加到 PATH - Mac/Linux:复制到
/usr/local/bin(命令:sudo mv mdbook /usr/local/bin/)
- Windows:复制到
验证安装:终端输入
mdbook --version,显示mdbook v0.4.52即成功。 - 访问 mdBook Releases 页面,下载对应系统的压缩包(如 Windows 选
-
注册一个Github账号,并新建一个Repsitory。
项目搭建
创建项目
1、创建本地项目目录:打开终端,执行以下命令创建并进入项目文件夹
# 替换为你的项目名(如 my-tech-notes)
mkdir my-tech-notes && cd my-tech-notes
2、执行 mdbook init 命令,自动生成基础目录结构,如下:
my-tech-notes/
├── book/ # 构建后生成的静态网页(自动生成,无需手动改)
├── src/ # 笔记核心目录(所有 Markdown 笔记放这里)
│ ├── chapter_1.md # 示例章节(可删除)
│ └── SUMMARY.md # 笔记导航目录(关键!定义章节结构)
└── book.toml # mdBook 配置文件(标题、主题、插件等)
配置项目
1、修改book.toml:配置项参考 官方文档
[book]
title = "我的技术笔记" # 笔记标题(将显示在网页顶部)
authors = ["Your Name"] # 作者名
language = "zh-CN" # 语言(中文)
src = "src" # 笔记源文件目录(默认无需改)
description = "记录编程、算法、工具使用的学习笔记" # 站点描述
[output.html]
search = true # 启用网页搜索功能(支持关键词查找笔记)
favicon = "src/assets/favicon.ico" # 网站图标(可选,需自行添加)
additional-css = ["src/assets/custom.css"] # 自定义样式(可选)
theme = "ayu" # 内置主题(可选:light/dark/ayu,也可自定义)
# (可选)启用数学公式支持(需后续安装插件)
[preprocessor.katex]
no-css = false
include-src = true
2、编写导航目录 src/SUMMARY.md:
SUMMARY.md是笔记的「目录索引」,决定网页左侧导航栏的结构。
# 目录
## 基础工具
- [前言](intro.md) # 笔记介绍页
- [Git 常用命令](tools/git.md) # 工具类笔记
- [Markdown 语法](tools/markdown.md)
## 编程学习
- [Rust 入门](programming/rust/basics.md)
- [JavaScript 异步编程](programming/js/async.md)
## 数学知识
- [线性代数基础](math/linear-algebra.md)
- [概率论笔记](math/probability.md)
## 附录
- [常见问题](appendix/faq.md)
规则说明:
- 目录层级用
##/###区分,对应导航栏的折叠层级 - 链接格式:
[章节名](文件路径),路径是src/下的相对路径 - 新增笔记后,必须在
SUMMARY.md中添加条目,否则不会显示在导航中
3、编写与预览笔记:根据 SUMMARY.md 的目录结构,在 src/ 下创建对应 Markdown 文件,如 src/tools/git.md
# Git 常用命令
## 基础操作
- 初始化仓库:`git init`
- 克隆远程仓库:`git clone https://github.com/your-username/your-repo.git`
- 查看状态:`git status`
## 提交代码
```bash
git add . # 添加所有修改
git commit -m "新增 Git 常用命令笔记" # 提交说明
git push origin main # 推送到远程
```
4、在 src/ 下创建 assets/ 文件夹,用于存放图片、附件等:
引用图片时用 相对路径(如
../assets/git-workflow.png),避免依赖外部图床(防止失效)
src/
└── assets/
├── git-workflow.png # 笔记中引用的图片
└── custom.css # 自定义样式文件
5、笔记预览:执行 mdbook serve 命令启动本地服务器,实时预览笔记效果,终端会输出访问地址(默认 http://localhost:3000),打开浏览器即可查看
- 左侧是
SUMMARY.md定义的导航栏 - 右侧是 Markdown 渲染后的内容
- 修改笔记后,网页会自动刷新(无需重启命令)
关联Github仓库
1、初始化本地Git仓库:在项目根目录执行
git init # 初始化 Git 仓库
git add . # 添加所有文件到暂存区
git commit -m "初始化 mdBook 笔记项目" # 提交第一版
2、关联远程仓库:
# 替换为你的仓库地址
git remote add origin https://github.com/your-username/my-tech-notes.git
# 推送到 GitHub(首次推送需输入 GitHub 账号密码或 Token)
git push -u origin main
3、在项目根目录创建 .gitignore,避免提交无关文件:
# 忽略 mdBook 构建产物
book/
# 忽略 IDE 配置文件
.idea/
.vscode/
# 忽略系统临时文件
.DS_Store
Thumbs.db
# 忽略缓存文件
.mdbook-cache/
Github自动部署
通过 GitHub Actions 实现「推送代码后自动构建并部署到 GitHub Pages」,无需手动操作。
1、创建 GitHub Actions 工作流文件:在项目根目录创建 .github/workflows/deploy.yml 文件,内容如下
name: Deploy mdBook to GitHub Pages
# 触发条件:仅当 main 分支的 src/、book.toml、工作流文件变更时触发
on:
push:
branches: ["main"]
paths:
- "src/**"
- "book.toml"
- ".github/workflows/deploy.yml"
# 允许手动触发(在 GitHub Actions 页面点击「Run workflow」)
workflow_dispatch:
# 权限配置(确保能部署到 Pages)
permissions:
contents: read
pages: write
id-token: write
# 并发控制:避免同时部署多个版本
concurrency:
group: "pages"
cancel-in-progress: false
jobs:
# 构建阶段:生成静态网页
build:
runs-on: ubuntu-latest
env:
MDBOOK_VERSION: 0.4.36 # 固定 mdBook 版本,避免兼容性问题
steps:
- name: 拉取 GitHub 代码
uses: actions/checkout@v4
- name: 安装 mdBook(预编译二进制,快速)
run: |
curl -L https://github.com/rust-lang/mdBook/releases/download/v${MDBOOK_VERSION}/mdbook-v${MDBOOK_VERSION}-x86_64-unknown-linux-gnu.tar.gz | tar xzf -
sudo mv mdbook /usr/local/bin/
- name: 安装数学公式插件(可选,若启用了 katex)
run: cargo install mdbook-katex
- name: 构建 mdBook 静态网页
run: mdbook build # 生成的文件在 book/ 目录
- name: 上传构建产物(供部署使用)
uses: actions/upload-pages-artifact@v3
with:
path: ./book # 上传 book/ 目录下的所有文件
# 部署阶段:将构建产物推送到 GitHub Pages
deploy:
needs: build # 依赖 build 阶段完成后才执行
runs-on: ubuntu-latest
environment:
name: github-pages
url: ${{ steps.deployment.outputs.page_url }} # 部署后显示访问地址
steps:
- name: 部署到 GitHub Pages
id: deployment
uses: actions/deploy-pages@v4
2、推送工作流文件到 GitHub:
git add .github/workflows/deploy.yml
git commit -m "添加 GitHub Actions 自动部署配置"
git push
3、配置 GitHub Pages:
- 打开 GitHub 仓库 → 点击顶部「Settings」→ 左侧「Pages」
- 在「Source」中选择「Deploy from a branch」→ 分支选择
gh-pages(由 GitHub Actions 自动创建) - 点击「Save」,等待 1-2 分钟,页面会显示访问地址(如
https://your-username.github.io/my-tech-notes/)
mdbook插件推荐
- mdbook-toc:自动生成目录
- mdBook-pagetoc:侧边栏目录
- mdbook-mermaid:流程图
Github Actions工作流
GitHub Actions 工作流是一项强大的自动化工具,它允许你在 GitHub 仓库中自动执行软件开发生命周期中的各种任务,如构建、测试、打包、发布和部署。
基础介绍
核心概念
GitHub Actions 的核心在于工作流(Workflow),它是一个可配置的自动化过程,由一个或多个作业(Jobs) 组成,每个作业又包含一系列步骤(Steps),这些步骤可以在特定事件(Event) 触发时在运行器(Runner) 上执行。
核心组件及其功能如下:
| 组件 (Component) | 说明 (Description) | 示例 (Example) |
|---|---|---|
| 工作流 (Workflow) | 可配置的自动化过程,定义在 .github/workflows目录下的 YAML 文件中。 | name: CI Pipeline |
| 事件 (Event) | 触发工作流运行的特定活动,如推送代码、创建 PR 等。 | on: [push, pull_request] |
| 作业 (Job) | 一组在同一运行器上执行的步骤序列。一个工作流可以包含多个作业,默认并行执行,也可配置依赖关系串行执行。 | jobs: build: runs-on: ubuntu-latest |
| 步骤 (Step) | 作业内的单个任务,可以运行命令或使用操作(Action)。 | - name: Checkout code uses: actions/checkout@v3 |
| 操作 (Action) | 可重用的代码单元,是工作流的最小构建块,可用于简化复杂流程。 | actions/checkout@v3(检出代码) |
| 运行器 (Runner) | 执行工作流的服务器。可以是 GitHub 提供的托管运行器(如 Ubuntu, Windows, macOS),也可以是用户自己配置的自托管运行器。 | runs-on: ubuntu-latest |
工作流文件结构
工作流文件采用 YAML 格式,通常包含以下部分:
name: 工作流的名称。on: 指定触发事件,例如push,pull_request,schedule(定时任务),或workflow_dispatch(手动触发)。jobs: 定义工作流中要执行的一个或多个作业。runs-on: 指定作业运行的虚拟机环境。steps: 定义作业中要执行的步骤序列。uses: 使用一个现有的 Action。run: 执行一个 shell 命令或脚本。name: 步骤的名称,便于在日志中识别。with: 为 Action 提供输入参数。env: 为步骤设置环境变量。
简单的工作流示例:
name: CI/CD Pipeline
on:
push:
branches: [ main ]
pull_request:
branches: [ main ]
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Set up environment
run: echo "Setting up environment"
- name: Build
run: echo "Building application"
- name: Test
run: echo "Running tests"
- name: Deploy
if: github.ref == 'refs/heads/main'
run: echo "Deploying to production"
主要应用场景
GitHub Actions 的应用场景非常广泛,主要包括:
- 持续集成 (CI):在代码提交后自动运行编译和测试,确保代码质量。例如,可以配置在每次推送代码或创建拉取请求时自动运行单元测试、集成测试。
- 持续部署 (CD):在代码通过测试后,自动部署到生产环境,如服务器、云平台(AWS、Azure)或容器平台(Kubernetes)。部署时可以结合策略如蓝绿部署或金丝雀发布以最小化风险。
- 自动化测试:执行单元测试、集成测试、端到端测试等,并生成测试报告。
- 发布管理:自动生成版本号、打包并发布到包管理器(如 npm、PyPI)。
- 自动化文档生成:从代码注释自动生成 API 文档并部署到 GitHub Pages 等平台。
- 定期任务:通过
schedule触发器执行定期任务,如清理缓存、安全检查等。
最佳实践
矩阵构建
矩阵构建(matrix strategy) 允许你使用单个作业配置,自动在多个环境、版本或平台组合下并行运行任务。
示例如下:下面配置会生成 2 * 3 个独立的作业,每个作业支持使用 matrix.<variable-name> 获取其上下文
jobs:
build:
strategy:
matrix:
node-version: [14.x, 16.x, 18.x]
os: [ubuntu-latest, windows-latest]
runs-on: ${{ matrix.os }}
steps:
- uses: actions/checkout@v3
- name: Use Node.js ${{ matrix.node-version }}
uses: actions/setup-node@v3
with:
node-version: ${{ matrix.node-version }}
include和exclude
为了更精细地控制矩阵组合,你可以使用 include和 exclude关键字。
include:用于向矩阵中添加额外的、非自动生成的组合,或为现有组合添加新的属性。exclude:用于移除自动生成的特定组合。
示例:
strategy:
matrix:
os: [ubuntu-latest, windows-latest, macOS]
node-version: [14.x, 16.x]
include:
# 添加一个未在原始矩阵中定义的 python-version 组合
- os: ubuntu-latest
node-version: 18.x # 与现有组合重复,但可以添加新属性
python-version: '3.11' # 新属性
- os: windows-latest
node-version: 20.x # 全新的组合
# 移除所有在 Windows 上运行 Node.js 14.x 的组合
- os: windows-latest
node-version: 14.x
# 移除所有在 macOS 上运行 Node.js 16.x 的组合
- os: macos-latest
node-version: 16.x
控制并行与失败策略
fail-fast(默认为 true):如果任一矩阵作业失败,则取消所有正在进行的作业。将其设置为 false可以让所有作业完成,从而获得完整的兼容性报告。
max-parallel:限制同时运行的矩阵作业数量,可用于控制资源消耗。
strategy:
fail-fast: false # 一个失败不会影响其他作业
max-parallel: 4 # 最多同时运行4个作业
matrix:
# ... 矩阵定义 ...
缓存优化
矩阵作业通常需要安装依赖。为不同组合创建高效的缓存至关重要。
- name: Cache dependencies
uses: actions/cache@v3
with:
path: |
~/.npm
node_modules
# 缓存键应包含矩阵变量,以便为不同组合创建独立缓存
key: ${{ runner.os }}-node-${{ matrix.node-version }}-${{ hashFiles('**/package-lock.json') }}
结果聚合
- 调试:使用
act工具在本地运行和调试矩阵工作流,无需反复提交代码。 - 结果聚合:使用
actions/upload-artifact和actions/download-artifact收集所有矩阵作业的测试结果(如覆盖率报告),并在最后一份作业中生成聚合报告。
完整示例
name: Python Matrix Test
on: [push, pull_request]
jobs:
test:
runs-on: ${{ matrix.os }}
strategy:
fail-fast: false
matrix:
# 定义主维度
python-version: ['3.8', '3.9', '3.10', '3.11']
os: [ubuntu-latest, windows-latest]
# 定义依赖安装策略维度
dependencies: [minimal, latest]
# 使用 include 为特定组合添加额外变量或覆盖原有变量
include:
- python-version: '3.8'
os: ubuntu-latest
torch-version: '1.13.1' # 为 PyTorch 等特定库固定旧版本
- python-version: '3.11'
os: ubuntu-latest
generate-coverage: true # 标记此组合用于生成最终覆盖率报告
# 使用 exclude 排除不兼容或不需要的组合
exclude:
- python-version: '3.8'
dependencies: 'latest' # Python 3.8 不测试最新依赖
- os: windows-latest
dependencies: 'latest' # Windows 上也不测试最新依赖
steps:
- name: Checkout code
uses: actions/checkout@v4
- name: Set up Python ${{ matrix.python-version }}
uses: actions/setup-python@v5
with:
python-version: ${{ matrix.python-version }}
cache: 'pip'
cache-dependency-path: requirements.txt
- name: Install dependencies (minimal)
if: matrix.dependencies == 'minimal'
run: pip install -r requirements.txt
- name: Install dependencies (latest)
if: matrix.dependencies == 'latest'
run: |
pip install -r requirements.txt
pip install --upgrade pip
pip-review --auto # 自动升级所有包到最新版本
- name: Run tests with pytest
run: pytest --cov=./ --cov-report=xml:coverage.xml -v
env:
PYTHONPATH: ${{ github.workspace }}
- name: Upload coverage report
if: always() # 即使测试失败也上传报告
uses: actions/upload-artifact@v3
with:
name: coverage-py-${{ matrix.python-version }}-${{ matrix.os }}
path: coverage.xml
# 一个汇总报告的作业,在所有矩阵作业完成后运行
combine-reports:
needs: test # 依赖 test 作业
runs-on: ubuntu-latest
if: always() # 即使有测试失败也运行
steps:
- name: Download all coverage artifacts
uses: actions/download-artifact@v3
with:
path: all-coverage-reports
pattern: coverage-*
merge-multiple: true
- name: Combine coverage reports
run: |
pip install coverage
python -m coverage combine all-coverage-reports/coverage-*.xml
python -m coverage report --show-missing
python -m coverage html
shell: bash
- name: Upload combined HTML report
uses: actions/upload-artifact@v3
with:
name: combined-coverage-report
path: htmlcov
缓存依赖
核心参数说明
GitHub Actions 的 actions/cache@v4是一个非常重要的工具,它能通过缓存依赖和构建产物来显著提升 CI/CD 流程的效率,避免重复下载和编译,从而节省时间和计算资源。
核心参数说明:
path:指定需要缓存的目录或文件的路径。可以是一个路径,也可以是多行字符串指定多个路径。key:缓存唯一的标识符。通常根据 runner 的操作系统、项目依赖文件(如package-lock.json)的哈希值等来生成。只有当key完全匹配时,才会恢复缓存。restore-keys:当没有找到与key完全匹配的缓存时,会尝试用restore-keys列表(按顺序)进行前缀匹配。这有助于找到相似的缓存,实现渐进式恢复。
缓存键(Key)策略:设计一个好的 key是高效利用缓存的关键。
| 策略 | 描述 | 示例 |
|---|---|---|
| 基于依赖文件哈希 | 最常用。依赖文件(如lock文件)内容变化时,缓存自动失效。 | key: ${{ runner.os }}-node-${{ hashFiles('**/package-lock.json') }} |
| 按操作系统分离 | 不同操作系统的依赖和构建产物通常不兼容,需分开缓存。 | key: ${{ runner.os }}-pip-${{ hashFiles('**/requirements.txt') }} |
| 复合键 | 结合多个维度(如OS、语言版本、项目)生成更精确的键。 | key: ${{ runner.os }}-py-${{ matrix.python-version }}-${{ hashFiles('**/requirements.txt') }} |
| 短期缓存 | 用于临时性需求,如调试。通常与工作流运行ID或提交SHA绑定。 | key: cache-${{ github.run_id }} |
不同语言的缓存设计
正确设置缓存路径(Path):路径设置是缓存恢复的关键。你需要根据操作系统和语言环境,准确指定需要缓存的目录。常见路径包括:
| 环境/工具 | 缓存路径(Linux示例) | 缓存内容 |
|---|---|---|
| Node.js/npm | ~/.npm | npm 缓存目录 |
| Python/pip | ~/.cache/pip | pip 缓存目录 |
| Rust/Cargo | ~/.cargo/registry, ~/.cargo/git, target | Cargo 注册表、git 依赖和构建输出 |
| Java/Gradle | ~/.gradle/caches, ~/.gradle/wrapper | Gradle 缓存和包装器 |
| 通用容器 | node_modules, venv, target/release | 项目级的依赖目录和输出 |
示例如下:
1、JavaScript (npm):缓存 npm 的缓存目录,而不是直接缓存 node_modules。
- name: Get npm cache directory
id: npm-cache-dir
shell: bash
run: echo "dir=$(npm config get cache)" >> ${GITHUB_OUTPUT}
- name: Cache npm dependencies
uses: actions/cache@v4
with:
path: ${{ steps.npm-cache-dir.outputs.dir }}
key: ${{ runner.os }}-node-${{ hashFiles('**/package-lock.json') }}
2、Python (pip):Python 的缓存路径因操作系统而异,在矩阵构建中需特别注意。
jobs:
build:
strategy:
matrix:
os: [ubuntu-latest, macos-latest, windows-latest]
include:
- os: ubuntu-latest
path: ~/.cache/pip
- os: macos-latest
path: ~/Library/Caches/pip
- os: windows-latest
path: ~\AppData\Local\pip\Cache
steps:
- uses: actions/cache@v4
with:
path: ${{ matrix.path }}
key: ${{ runner.os }}-pip-${{ hashFiles('**/requirements.txt') }}
3、Java (Maven):Maven 的依赖默认存储在 .m2目录下。
- uses: actions/cache@v4
with:
path: ~/.m2/repository
key: ${{ runner.os }}-maven-${{ hashFiles('**/pom.xml') }}
4、Java (Gradle):Gradle 缓存包括依赖和包装器。
注意:缓存 Gradle 时需确保 Gradle 守护进程已停止,避免文件锁定。
- uses: actions/cache@v4
with:
path: |
~/.gradle/caches
~/.gradle/wrapper
key: ${{ runner.os }}-gradle-${{ hashFiles('**/*.gradle*') }}
5、Go:Go 的缓存路径也因操作系统不同而变化。
- uses: actions/cache@v4
with:
path: |
~/.cache/go-build # Linux
~/go/pkg/mod # Go module cache
key: ${{ runner.os }}-go-${{ hashFiles('**/go.sum') }}
缓存命中检查
可以通过 outputs判断缓存是否命中,从而决定是否跳过安装步骤。
- name: Check cache
id: cache-check
uses: actions/cache@v4
with:
path: ${{ matrix.path }}
key: ...
- name: Install dependencies
if: steps.cache-check.outputs.cache-hit != 'true'
run: pip install -r requirements.txt
缓存键重用
保存缓存时重用键:在 save阶段重用 restore阶段计算出的键,避免重复计算。
- uses: actions/cache/restore@v4
id: restore-cache
with:
path: path/to/dependencies
key: ${{ runner.os }}-key-${{ hashFiles('**/lockfile') }}
- # ... build steps that may change the dependencies ...
- uses: actions/cache/save@v4
with:
path: path/to/dependencies
key: ${{ steps.restore-cache.outputs.cache-primary-key }}
分支缓存隔离与共享
分支缓存隔离与共享:为不同分支创建独立的缓存,但允许回退到主分支缓存。
- uses: actions/cache@v4
with:
path: path/to/dependencies
key: ${{ runner.os }}-npm-${{ github.ref_name }}-${{ hashFiles('**/package-lock.json') }}
restore-keys: |
${{ runner.os }}-npm-main- # 回退到主分支缓存
${{ runner.os }}-npm- # 最后回退到任何npm缓存
缓存最佳实践
- 缓存内容:优先缓存依赖管理工具的缓存目录(如
~/.npm、~/.cache/pip),而非直接缓存node_modules或target等构建输出目录。后者可能更大且效果不佳。 - 缓存限制:GitHub 对缓存有容量和时间限制。每个仓库的缓存总大小限制为 10GB,如果超过此限制,最早创建的缓存将被删除。
- 避免缓存污染:确保
key中包含足够唯一的标识(如依赖文件哈希),防止依赖变更后仍使用旧的缓存。 - 清理缓存:定期清理无用缓存。可以使用 GitHub API 或在工作流中添加清理步骤。
- name: Clean old cache files
run: |
find ~/.gradle/caches -type f -mtime +30 -delete
变量管理
secrets
安全管理敏感信息:切勿将密码、API 密钥等敏感信息直接写入工作流文件。应使用 GitHub 仓库设置中的 Secrets 功能安全地存储和引用它们。
Github Secrets允许你在仓库或组织级别加密存储敏感数据,这些数据在工作流运行时会通过环境变量注入,并且 GitHub 会自动屏蔽日志中的这些值以防泄露。支持创建如下三种Secret:
| 类型 | 创建位置 | 访问范围 | 适用场景 |
|---|---|---|---|
| 仓库级 Secret | 仓库 Settings → Secrets and variables → Actions | 仅限该仓库 | 单个仓库专用的密钥,如部署到特定服务器的 SSH 私钥 |
| 组织级 Secret | 组织 Settings → Secrets and variables → Actions | 组织内所有仓库或指定仓库 | 在多个仓库间共享的密钥,如统一的 Docker Hub 账号 |
| 环境级 Secret | 仓库 Settings → Environments → 具体环境 | 需在作业中指定 environment时才可访问 | 为不同环境(如测试、生产)提供差异化配置,如生产环境的数据库密码 |
在工作流中使用Secrets:通过 ${{secrets.SECRET_NAME}}来引用配置的Secret
jobs:
build:
runs-on: ubuntu-latest
env:
# 在作业级别定义环境变量,所有步骤均可使用,不推荐
DEPLOY_TOKEN: ${{ secrets.API_KEY }}
steps:
- name: Checkout code
uses: actions/checkout@v4
- name: 使用环境变量示例
run: echo "使用密钥进行操作" # 在脚本中通过 $DEPLOY_TOKEN 访问
- name: 安全使用 Secret 示例
env:
# 在步骤级别设置环境变量,推荐方式
MY_SECRET: ${{ secrets.API_KEY }}
DB_PASSWORD: ${{ secrets.DB_PASSWORD }}
run: |
# 在脚本中使用环境变量,而不是直接引用 secrets
curl -H "Authorization: Bearer $MY_SECRET" https://api.example.com/data
./my_script --db-pass="$DB_PASSWORD" # 通过参数传递也更安全
- name: 直接引用 Secret
run: echo "密钥是 ${{ secrets.API_KEY }}" # ❌ 不推荐,值虽会被屏蔽,但可能有日志泄露风险
- name: 使用 SSH 连接到服务器
uses: appleboy/ssh-action@v1
with:
host: ${{ secrets.SERVER_HOST }}
username: ${{ secrets.SSH_USERNAME }}
key: ${{ secrets.SSH_PRIVATE_KEY }} # 传递 SSH 私钥
script: sudo deploy.sh
基于环境的条件访问:通过指定environment来使用该环境下配置的特定secrets
jobs:
deploy-prod:
runs-on: ubuntu-latest
environment: production # 指定环境,从而使用该环境下的 Secrets
steps:
- name: 部署到生产环境
env:
PROD_API_KEY: ${{ secrets.PROD_API_KEY }} # 使用 production 环境下的 Secret
run: ./deploy.sh --env=production
在矩阵构建中动态选择secrets:利用矩阵策略和 format函数动态生成要引用的 Secret 名称
jobs:
deploy:
runs-on: ubuntu-latest
strategy:
matrix:
env: [staging, production] # 定义矩阵变量
steps:
- name: 动态选择 Secret
env:
# 根据矩阵变量动态生成 Secret 名称,例如 secrets.STAGING_API_KEY 或 secrets.PROD_API_KEY
API_KEY: ${{ secrets[format('{0}_API_KEY', matrix.env)] }}
run: ./deploy.sh --env=${{ matrix.env }}
secrets 安全管理最佳实践:
-
遵循最小权限原则:只为 Secret 分配完成任务所需的最小权限
-
严防日志泄露
-
避免在命令中直接输出:如
echo "${{ secrets.KEY }}"。虽然 GitHub 会尝试屏蔽,但仍有风险。 -
避免通过命令行参数传递:命令行参数可能会被进程列表捕获。优先使用环境变量或配置文件。
# 不推荐 - run: ./script.sh --password=${{ secrets.DB_PASSWORD }} # ❌ # 推荐 - env: DB_PASS: ${{ secrets.DB_PASSWORD }} run: ./script.sh # ✅ 脚本内部从 $DB_PASS 环境变量读取
-
-
谨慎审核第三方 Actions:在将 Secrets 传递给第三方 Actions(如
with:或env:)时,务必审查其代码是否可信,防止恶意代码窃取密钥。 -
处理 Pull Request 的安全:来自外部分支的 Pull Request 默认无法访问仓库 Secrets。切勿在由
pull_request事件触发的工作流中执行敏感操作或访问 Secrets。应使用push事件(例如在合并到主分支后)来触发部署流程。 -
定期轮换密钥:制定计划定期更新 Secrets(例如每 90 天)。你可以使用 GitHub API 和 Personal Access Token 自动化这一过程。
-
审计与监控:定期检查 GitHub 组织的审计日志,监控 Secrets 的创建、修改和访问情况。
-
公共仓库禁用敏感 Secrets:绝对不要在公共仓库中使用真正敏感的 Secrets,因为恶意用户可能通过构造特殊的工作流来窃取它们。
常见问题:
-
Secret 未生效:首先检查 Secret 名称的拼写和大小写是否与引用处完全一致。确认 Secret 已正确添加到预期的范围(仓库、组织或环境)。
-
在 PR 中无法访问 Secret:这是出于安全考虑的设计。如果确实需要,可考虑使用
pull_request_target事件,但务必了解其安全风险并添加额外防护条件(例如仅允许来自本仓库的 PR)。 -
本地开发如何模拟:在项目根目录创建
.env文件,并使用git update-index --assume-unchanged .env或将其添加到.gitignore中来避免提交。在工作流中,可以通过步骤生成这些环境变量。# .env 文件示例 API_KEY=your_local_api_key_here DB_PASSWORD=your_local_db_password_here
vars
GitHub Actions 中的 vars上下文用于访问在仓库级别、组织级别或环境级别定义的配置变量。这些变量通常用于存储非敏感的配置信息,例如资源路径、功能标志或服务器名称。
| 方面 | 说明 | 示例或用法 |
|---|---|---|
| 定义位置与优先级 | 变量可在环境、仓库、组织级别定义。环境级变量优先级最高,其次为仓库级,最后是组织级。 | 定义路径:仓库 Settings → Secrets and variables → Actions → Variables tab。 |
| 访问方式 | 在工作流文件中使用 ${{ vars.VARIABLE_NAME }}语法引用。 | ${{ vars.API_BASE_URL }} |
| 与 Secrets 区别 | vars用于非敏感配置信息,值会以明文形式存储在日志中。敏感信息务必使用 secrets。 | 数据库密码应使用 secrets,部署环境标识可使用 vars。 |
| 常用场景 | 配置不同环境(如开发、生产)的参数,设置构建标志,共享公共资源路径等。 | environment: ${{ vars.ENVIRONMENT }} |
定义配置变量:
- 仓库级别:在仓库的 Settings > Secrets and variables > Actions > Variables 标签页下,点击 New repository variable 来添加。此变量仅对该仓库可见。
- 组织级别:在组织的 Settings > Secrets and variables > Actions > Variables 标签页下,点击 New organization variable 来添加。你可以选择让变量对所有仓库可见,或仅限选择的仓库。
- 环境级别:在仓库的 Settings > Environments 下,选择或创建一个环境,然后在其 Environment variables 部分添加。此变量仅对引用该环境的工作流作业可见。
变量名称限制:
- 名称只能包含字母数字字符(
[a-z],[A-Z],[0-9])或下划线(_)。 - 不能以
GITHUB_前缀开头。 - 不能以数字开头。
- 不区分大小写。
- 在创建它的仓库、组织或环境中必须唯一。
配置变量数量和大小限制:
- 单个变量大小限制为 48 KB。
- 一个组织最多可存储 1,000 个变量,一个仓库最多 500 个变量,一个环境最多 100 个变量。
- 组织和仓库变量的总大小限制为每个工作流运行 10 MB(环境级别变量不计入此限制)。
工作流中变量使用示例:
name: Deployment
on:
workflow_dispatch: # 手动触发工作流
env:
# 可以从 vars 中取值来设置环境变量
DEPLOYMENT_ENV: ${{ vars.ENVIRONMENT }}
jobs:
deploy:
runs-on: ubuntu-latest
environment: ${{ vars.ENVIRONMENT }} # 使用变量指定环境
steps:
- name: Checkout code
uses: actions/checkout@v4
- name: Debug variables
run: |
echo "Deploying to: $DEPLOYMENT_ENV"
echo "API URL: ${{ vars.API_BASE_URL }}"
echo "Max retries: ${{ vars.MAX_RETRIES }}"
- name: Deploy to server
if: ${{ vars.SHOULD_DEPLOY == 'true' }} # 使用变量控制步骤执行
run: ./deploy.sh --env $DEPLOYMENT_ENV
注意事项:
- 变量优先级:如果同名变量在多个级别定义,环境级变量优先级最高,其次是仓库级,最后是组织级。
- 可重用工作流:在可重用工作流中,使用的是调用方工作流仓库的变量。被调用工作流仓库中定义的变量对调用方不可用。
- 默认环境变量:GitHub 还提供了一系列默认环境变量(如
GITHUB_REPOSITORY),它们与vars上下文不同,通常以GITHUB_或RUNNER_开头,并且是只读的。
secrets、vars、env对比
| 特性 | vars(配置变量) | env(环境变量) | secrets(机密) |
|---|---|---|---|
| 用途 | 非敏感配置 | 主要在工作流内部定义非敏感数据 | 敏感信息(如密钥、令牌) |
| 定义位置 | 仓库、组织、环境设置 | 工作流文件内部 (env关键字) | 仓库、组织、环境设置 |
| 访问方式 | ${{ vars.VAR_NAME }} | ${{ env.VAR_NAME }}或 $VAR_NAME | ${{ secrets.SECRET_NAME }} |
| 日志显示 | 明文显示 | 明文显示(除非手动屏蔽) | 自动屏蔽 |
| 适用范围 | 可跨仓库(组织变量) | 仅限于定义它的工作流、作业或步骤 | 可跨仓库(组织机密) |
最佳实践:
- 绝不将密码、API 密钥等敏感信息存入
vars,务必使用secrets。 - 对于需要在不同工作流或仓库间共享的非敏感配置,
vars(特别是组织变量)非常有用。 - 对于工作流内部使用的临时变量或脚本使用的变量,使用
env更合适。
优化工作流结构
- 使用
needs关键字来定义作业之间的依赖关系,确保它们按顺序执行。 - 使用
if条件语句来控制步骤或作业仅在特定条件下运行。 - 将复杂的工作流分解为多个更小、更专注的工作流文件。
- 为长时间运行的作业设置
timeout-minutes,避免资源浪费。
查看日志和调试
作流运行后,可以在 GitHub 仓库的 "Actions" 标签页下查看详细日志,这有助于排查失败原因。可以使用 actions/upload-artifactAction 上传构建产物或日志文件以便进一步分析。
部署模式
Github Actions的自动化部署流程主要支持如下两种部署方式:
flowchart TD
A[代码推送事件触发] --> B[构建阶段<br>检出代码、安装环境、执行构建]
B --> C{选择部署方式}
C --> D[传统方式: gh-pages分支]
D --> D1[推送构建产物<br>到gh-pages分支]
D1 --> D2[GitHub Pages自动<br>从gh-pages分支部署]
D2 --> F[部署完成]
C --> E[现代方式: Pages Artifact]
E --> E1[上传构建产物<br>为Artifact]
E1 --> E2[Deploy Pages Action<br>读取Artifact并部署]
E2 --> F
F --> G[通知与监控]
部署到gh-pages分支
部署到gh-pages是早期的主流做法,通过将构建的好的静态文件推送到仓库内一个单独的gh-pages分支来实现部署。
示例:
name: Deploy to GitHub Pages (Old)
on:
push:
branches: [ main ]
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@v4 # 检出代码
- name: Install and Build
run: |
npm install
npm run build # 执行项目构建
- name: Deploy to gh-pages branch
uses: peaceiris/actions-gh-pages@v3 # 使用第三方Action
with:
github_token: ${{ secrets.GITHUB_TOKEN }} # 使用GITHUB_TOKEN认证
publish_dir: ./dist # 指定构建输出目录
Pages Artifact
Pages Artifact:将构建产物打包为一个 artifact上传,最后由专门的 Action 将其部署到 GitHub Pages。
示例:
name: Deploy to GitHub Pages (Modern)
on:
push:
branches: [ main ]
permissions: # ⚠️ 必须配置权限
contents: read
pages: write
id-token: write
jobs:
build:
runs-on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@v4
- name: Setup Node.js
uses: actions/setup-node@v4
with:
node-version: '20'
cache: 'npm' # 缓存依赖以加速构建
- name: Install dependencies
run: npm ci # 更严格、更快的依赖安装
- name: Build
run: npm run build
- name: Upload artifact
uses: actions/upload-pages-artifact@v3 # ⚡ 上传产物
with:
path: './dist' # 指定构建输出目录
deploy:
needs: build # 依赖build任务
runs-on: ubuntu-latest
environment:
name: github-pages
url: ${{ steps.deployment.outputs.page_url }} # 获取部署后的URL
steps:
- name: Deploy to GitHub Pages
uses: actions/deploy-pages@v4 # ⚡ 官方部署Action
配置注意事项:
- 权限配置 (必须):必须在工作流文件中显式声明
permissions,或是在仓库的Settings > Actions > General中授予工作流读写权限。 - 环境设置:部署任务中的
environment配置是可选的,但设置后可以在仓库的Environments中查看每次部署的详细记录。
自定义域名和HTTPS
为 GitHub Pages 设置自定义域名和 HTTPS 可以让你的网站看起来更专业、更安全。整个过程主要分为配置域名解析、在 GitHub 中设置以及验证 HTTPS 几个关键步骤。
前期准备
- 拥有一个 GitHub Pages 站点:你的
<username>.github.io仓库或配置为 GitHub Pages 的项目仓库应已构建并可通过默认地址访问。 - 拥有一个自定义域名:你需要在域名注册商(如阿里云、腾讯云、GoDaddy、Namecheap 等)购买一个域名。
配置自定义域名
配置DNS解析记录
登录你的域名注册商管理后台,找到 DNS 解析设置。根据你的需求选择以下一种或两种方式配置。
1、为根域名(如 example.com)配置:你需要添加 4 条 A 记录,将域名指向 GitHub Pages 的 IP 地址。这是为了冗余和负载均衡,提升可用性。
| 主机记录 (Name) | 记录类型 (Type) | 记录值 (Value / IP) |
|---|---|---|
@ | A | 185.199.108.153 |
@ | A | 185.199.109.153 |
@ | A | 185.199.110.153 |
@ | A | 185.199.111.153 |
2、为子域名(如 www.example.com)配置:
添加 1 条 CNAME 记录,将子域名指向你的 GitHub Pages 默认域名。
| 主机记录 (Name) | 记录类型 (Type) | 记录值 (Value) |
|---|---|---|
www | CNAME | <username>.github.io |
在Github仓库中设置
- 进入你的 GitHub Pages 对应的仓库。
- 点击 Settings 选项卡。
- 在左侧边栏中找到 Pages。
- 在 Custom domain 字段中,输入你的自定义域名(例如
www.example.com或example.com),然后点击 Save。 - 建议:为了确保自定义域名设置持久化,最好在仓库的根目录下创建一个名为
CNAME的文件(无后缀),内容就是你的自定义域名(如example.com),然后提交该文件。
启用HTTPS
GitHub Pages 默认会自动为你的站点提供 HTTPS 支持。但在你配置自定义域名后,可能需要手动启用或等待其自动配置。
- 在仓库的 Settings > Pages 页面,找到 Enforce HTTPS 选项。
- 如果它尚未被勾选,并且不是灰色不可用状态,请勾选它。
- 如果该选项暂时不可用,通常意味着 GitHub 正在为你的自定义域名申请和配置 SSL 证书,这个过程可能需要几分钟到几小时。请耐心等待,并时不时回来查看,一旦可用,立即勾选。
启用 HTTPS 后,访问你的网站将会通过安全的加密连接,并且浏览器地址栏会显示锁形图标。
注意事项:
- 混合内容警告:开启 HTTPS 后,如果你的网页通过
http://加载了图片、CSS 或 JavaScript 等资源,浏览器会报“混合内容”错误,部分资源可能被阻止加载。请确保网页中所有资源的链接都是相对路径或使用了https://。 - “HTTPS 选项不可用或无法开启”:检查你的 DNS 配置中是否包含了任何非 GitHub 的 IP 或地址,这可能会干扰证书签发。
CSS3入门
引入方式
CSS 常用的引入方式如下:
| 引入方式 | 语法/位置 | 作用范围 | 权重 | 开发建议 |
|---|---|---|---|---|
| 行内样式 | HTML元素的 style属性 | 仅当前元素 | 最高 (1,0,0,0) | 慎用,仅用于动态样式或最高优先级覆盖。 |
| 内部样式表 | HTML的 <head>中的 <style>标签 | 当前HTML文档 | 取决于选择器 | 临时使用,适合Demo或单页特有样式。 |
| 外部样式表 | 通过 <link>标签链接独立的 .css文件 | 所有引入该文件的页面 | 取决于选择器 | 强烈推荐,是项目开发的标准方式。 |
@import规则 | 在 <style>标签或 .css文件内部 | 当前样式表及引入的样式表 | 取决于选择器 | 避免直接使用,应由构建工具管理。 |
行内样式
将CSS规则直接写在HTML元素的 style属性中。
代码示例:
<p style="color: #ff4757; font-weight: bold;">这是一个重要的提示。</p>
<button style="padding: 8px 16px; background-color: #2ed573; border: none; border-radius: 4px;">点击我</button>
详细说明:
- 优先级:拥有最高的样式权重(
1,0,0,0),可以覆盖其他任何方式定义的样式(除非使用!important且权重更高)。 - 优点:极致精准,立即生效,便于用JavaScript直接操作(如
element.style.color = ‘blue’)。 - 缺点:
- 严重违反“内容与表现分离” 的原则,导致HTML结构混乱,难以维护。
- 样式无法复用,同样的样式需要在多个元素上重复编写,增加代码量。
- 会阻塞渲染(尽管单个影响小,但大量使用会影响页面首次绘制)。
- 适用场景:
- 收到动态数据后,由JavaScript实时计算并注入的样式(例如,一个可拖动元素的实时位置)。
- 在旧内容管理系统或特定框架中,用于微调某个元素的样式且确保一定能生效。
- 编写HTML电子邮件时,为保证兼容性常大量使用。
内部样式表
-
概念:将CSS规则集中写在HTML文档
<head>部分的<style>标签内。 -
代码示例:
<!DOCTYPE html> <html lang="zh-CN"> <head> <meta charset="UTF-8"> <title>内部样式表示例</title> <style> /* 在这里编写页面所有的CSS */ body { font-family: ‘Microsoft YaHei‘, sans-serif; background-color: #f8f9fa; } .container { width: 1200px; margin: 0 auto; } .highlight { background-color: yellow; padding: 5px; } </style> </head> <body> <div class="container"> <p class="highlight">这个段落被高亮了。</p> </div> </body> </html> -
详细说明:
- 优先级:其内部的CSS选择器按正常权重计算(如
.class权重为0,1,0,0)。 - 优点:
- 实现了页面级的样式与结构分离,比行内样式更易于维护。
- 可以在单个文件内快速编写和预览效果,适合学习或制作简单的独立页面。
- 缺点:
- 样式无法跨页面复用。如果多个页面需要相同样式,必须在每个页面重复编写。
- 增加了单个HTML文件的体积,且无法被浏览器单独缓存,当用户访问同一网站的不同页面时,需要重复下载这些样式。
- 适用场景:
- 快速原型、Demo或练习项目。
- 只有一个页面的小型网站。
- 该页面拥有完全不与其他页面共享的独特样式。
- 优先级:其内部的CSS选择器按正常权重计算(如
外部样式表
-
概念:将CSS规则保存在一个或多个独立的
.css文件中,通过HTML的<link>标签引入。 -
代码示例:
HTML文件 (index.html):
<!DOCTYPE html> <html lang="zh-CN"> <head> <meta charset="UTF-8"> <title>我的网站</title> <!-- 引入公共重置样式和主样式 --> <link rel="stylesheet" href="css/reset.css"> <link rel="stylesheet" href="css/main.css"> <!-- 可以引入多个CSS文件 --> </head> <body> <!-- 页面内容 --> </body> </html>CSS文件 (css/main.css):
/* 这是一个独立的CSS文件 */ .header { height: 60px; } .nav-item { display: inline-block; } .btn-primary { background: linear-gradient(to right, #4776E6, #8E54E9); color: white; } -
详细说明:
- 优先级:与内部样式表同级,取决于选择器权重。
- 优点:
- 彻底分离与最佳实践:完全实现HTML(结构)、CSS(表现)、JS(行为)的分离,代码结构清晰,利于团队协作和维护。
- 高效复用与缓存:同一个CSS文件可以被网站所有页面引用。浏览器会缓存该文件,用户首次加载后,访问其他页面无需重复下载,极大提升加载速度和用户体验。
- 便于项目管理与优化:可以按模块(如
layout.css,form.css)拆分样式文件,方便管理。生产环境中,可以使用构建工具(如Webpack、Vite)将它们合并、压缩,进一步优化性能。
- 缺点:在开发阶段,会产生额外的HTTP请求。但在HTTP/2多路复用普及后影响减小,且生产环境可通过打包合并来优化。
- 适用场景:所有正式的前端项目,无一例外都应作为首选方式。
@import规则
一种在CSS文件内部或<style>标签内引入其他CSS文件的方法,由CSS解析器处理。
在主CSS文件中引入:
/* main.css */
@import url(‘reset.css‘); /* 引入重置样式 */
@import url(‘components/buttons.css‘); /* 引入按钮组件样式 */
body {
font-size: 16px;
}
在HTML的<style>标签中使用(不推荐):
<style>
@import url(‘theme.css‘);
p { color: #333; }
</style>
详细说明:
- 优先级:被引入文件中的规则,其权重正常计算。
- 工作机制与问题:
- 串行加载:浏览器必须先下载、解析包含
@import的CSS文件,遇到@import指令后,才会开始下载被引入的CSS文件。这严重阻碍了并行加载,可能显著增加页面整体渲染时间。 - 不利于性能优化:无法通过
<link>标签的media属性或rel=‘preload‘等方式进行更细粒度的资源加载控制。
- 串行加载:浏览器必须先下载、解析包含
- 现代用法:在基于Webpack、Vite等构建工具的项目中,可以在JavaScript或CSS模块中使用
@import(或ES Module的import)语句来声明依赖。构建工具会在打包阶段处理这些指令,将它们合并或生成最优的资源加载策略,从而规避了浏览器中原生@import的性能缺陷。
适用场景:
- 在由构建工具管理的现代化前端项目中使用。
- 需要根据媒体查询条件加载不同的CSS文件(例如
@import url(‘print.css‘) print;),但这种需求现在更推荐使用<link>的media属性实现。
最佳实践
- 首选方式:对于项目样式,无条件使用
<link>引入外部样式表。 - 避免使用:
- 避免在生产环境中直接使用
@import引入关键样式。 - 尽量避免使用行内样式,除非是动态样式或特定框架(如React的
style对象)要求。
- 避免在生产环境中直接使用
- 合理使用:
- 内部样式表可用于极小的单页demo或与当前页面强绑定的独特样式。
@import可在由构建工具处理的CSS模块化代码中使用,或用于按媒体查询条件加载CSS。
- 性能与缓存:外部样式表能被浏览器缓存,是提升网站二次加载速度的关键。应利用构建工具对CSS进行合并与压缩。
选择器
基础选择器
| 选择器类型 | 语法示例 | 描述与作用 | 权重值 (Specificity) | 代码示例与解释 |
|---|---|---|---|---|
| 通配选择器 | * | 匹配文档中的所有元素。常用于重置默认样式(如 margin, padding)。 | 0,0,0,0 | * { margin: 0; padding: 0; box-sizing: border-box; }解释:将所有元素的边距、内边距设为0,并设置为边框盒模型。 |
| 元素选择器 | div、p、h1 | 根据HTML标签名来选择元素。也称为“标签选择器”。 | 0,0,0,1 | p { color: #333; line-height: 1.6; } 解释:选择所有 <p>段落元素,并设置其文字颜色和行高。 |
| 类选择器 | .className | 根据元素的 class属性值来选择。一个元素可以有多个类,一个类也可用于多个元素。最常用的选择器之一。 | 0,0,1,0 | <div class="box active"></div> .box { border: 1px solid #ccc; } .active { background-color: yellow; } 解释: .box选中所有 class包含 box的元素;.active会为元素添加黄色背景。 |
| ID 选择器 | #idName | 根据元素的 id属性值来选择。ID在文档中应是唯一的。权重很高,应谨慎使用。 | 0,1,0,0 | <header id="main-header"></header> #main-header { height: 60px; background: blue; }解释:选中 id为 main-header的唯一元素,并设置其样式。 |
| 属性选择器 | [attr]、[attr=value] | 根据元素的属性及属性值来选择元素。非常灵活。 | 0,0,1,0 (与类选择器同级) | 1. [disabled] { opacity: 0.5; } 选中所有带有 disabled属性的元素。 2. input[type="text"] { border-color: blue; } 选中 type属性为 text的 <input>元素。3. a[href^="https"](以...开头), a[href$=".pdf"](以...结尾) 等。 |
| 后代选择器 | selectorA selectorB | (空格连接)选择 selectorA 元素内部的所有后代 selectorB 元素。 | 权重为所有部分之和 | .article p { text-indent: 2em; } 解释:选中所有在 class="article"的元素内部的 <p>元素,无论嵌套多深。 |
| 子元素选择器 | selectorA > selectorB | (大于号连接)选择 selectorA 元素的直接子元素 selectorB。只匹配一代。 | 权重为所有部分之和 | .menu > li { border-bottom: 1px solid #eee; } 解释:只选中 .menu下一级的 <li>子元素,不会选中更深的 <li>。 |
| 相邻兄弟选择器 | selectorA + selectorB | (加号连接)选择 紧跟在 selectorA 之后 的第一个同辈 selectorB 元素。 | 权重为所有部分之和 | h2 + p { margin-top: 0; } 解释:选中紧跟在 <h2>后面的第一个 <p>段落。 |
| 通用兄弟选择器 | selectorA ~ selectorB | (波浪号连接)选择 selectorA 之后的所有同辈 selectorB 元素。 | 权重为所有部分之和 | .active ~ li { color: gray; } 解释:选中所有在 .active类元素之后的同级 <li>元素。 |
| 群组选择器 | selA, selB, selC | (逗号连接)同时选中多个选择器对应的元素,并为它们应用相同的样式。 | 各自独立计算,不叠加 | h1, h2, .title, #main-heading { font-family: ‘Microsoft YaHei’; } 解释:将上述列出的所有标题、类、ID 的字体统一设置为微软雅黑。 |
说明:
- 权重顺序:!important> 行内样式 > ID选择器 > 类/属性/伪类选择器 > 元素/伪元素选择器 > 通配选择器
- 组合使用:这些基础选择器可以通过空格、
>、+、~、,等符号灵活组合,以精准定位目标元素 - 开发建议:优先使用类选择器,它复用性高且权重适中。谨慎使用ID选择器和
!important,以免导致样式难以管理和覆盖
windows
Windows&Office激活:
- MAS:
- 云萌:
# 以管理员运行PowerShell并执行
irm https://get.activated.win | iex
office Tool Plus,Office下载工具:https://otp.landian.vip/zh-cn/
Jetbrains全家桶破解及激活码:https://3.jetbra.in/
git
配置http代理
Git配置http代理:
# 配置socks5代理
git config --global http.proxy socks5 127.0.0.1:7890
git config --global https.proxy socks5 127.0.0.1:7890
# 配置http代理
git config --global http.proxy 127.0.0.1:7890
git config --global https.proxy 127.0.0.1:7890
# 查看代理配置
git config --global --get http.proxy
git config --global --get https.proxy
# 取消代理配置
git config --global --unset http.proxy
git config --global --unset https.proxy
笔记工具
常用的笔记工具:
MkDocs快速入门
MkDocs官方文档:https://www.mkdocs.org/user-guide/
安装MkDocs
MkDocs需要Python和Python package manager pip,可以使用pip进行安装:
# 安装mkdocs
pip install mkdocs
# 检查安装
mkdocs -V
# 显示帮助
mkdocs -h
创建项目
切换到指定目录,执行如下命令创建项目:
mkdocs new blog
执行成功后,会在对应目录生成blog文件夹,文件夹下有如下内容:
- mkdocs.yml:配置文件,文档结构与主题设置
- docs:撰写的Markdown文档
- index.md:默认首页
MkDocs包含了一个内建的服务器,可以在本地预览当前文档。在项目文件夹下打开命令提示符,执行如下命令启动服务:
mkdocs serve
执行成功后,在浏览器打开 http://127.0.0.1:8000/ 进行访问。
配置
MkDocs官方配置文档: https://www.mkdocs.org/user-guide/configuration/
站点配置:
# 站点名称
site_name: "My Notes"
# 站点URL
site_url: "http://<domain>:<port>/<project>"
# 站点作者
site_author: ""
# 站点描述
site_description: ""
# 版权信息
copyright: ""
# 站点仓库URL
repo_url: ""
配置文档结构:
# 默认基于docs目录,只需要填写相对路径
# 如果不想使用默认目录,可以使用docs_dir来指定对应的文件夹名称
nav:
- "index.md"
- Python:
- 环境搭建: "python/install.md"
- 镜像配置: "python/pip.md"
- "about.md"
- "license.md"
主题配置:第三方主题 https://github.com/mkdocs/mkdocs/wiki/MkDocs-Themes
# MkDocs内置主题:mkdocs、readthedocs
theme: readthedocs
# 使用第三方主题
# 1. 下载主题
pip install mkdocs-rtd-dropdown
# 2. 在mkdocs.yml中配置
theme: rtd-dropdown
扩展
MkDocs 使用 Python-Markdown 库(Markdown 规范的 Python 实现)来渲染 Markdown 内容,因此 MkDocs 中对于 Markdown 内容渲染的扩展也是来自于此。我们可以在 Python-Markdown 的 官方文档 中浏览到目前所支持的 Markdown 扩展有哪些。
如使用下面配置开启对于 Markdown 内容标题的固定标识符、脚注以及表格:
markdown_extensions:
- toc:
permalink: True
- footnotes
- tables
站点发布
使用Github Pages发布站点:
1、在Github新建仓库
2、在本地MkDocs项目中初始化:
# 初始化
git init
# 将项目文件添加到暂存区
git add .
# 提交
git commit -m "first commit"
# 创建分支
git branch -M main
# 添加远端仓库
git remote add origin git@github.com:ZhSMM/note.git
# 推送
git push -u origin main
3、部署,在项目根路径执行如下命令:
mkdocs gh-deploy
mdbook
拥抱大模型
在Windows上安装Stable Diffusion
在Windows上使用ComfyUI安装Stable Diffusion步骤:
- 下载ComfyUI
- 下载指定的Stable Diffusion模型
- 将模型放入ComfyUI
- 运行
注意事项:运行绘图时,Prompt仅支持输入英文,不支持中文。
ComfyUI
Github:https://github.com/comfyanonymous/ComfyUI
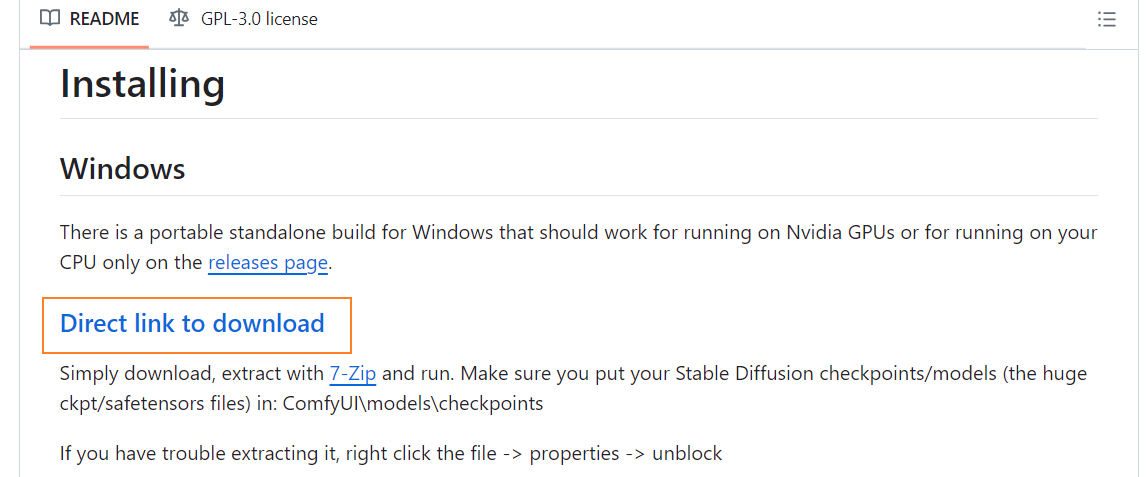
点击如上图所示按钮进行下载,并解压,然后根据机器上是否存在Nvida显卡,再决定是使用run_cpu或run_nvida_gpu,双击执行即可:
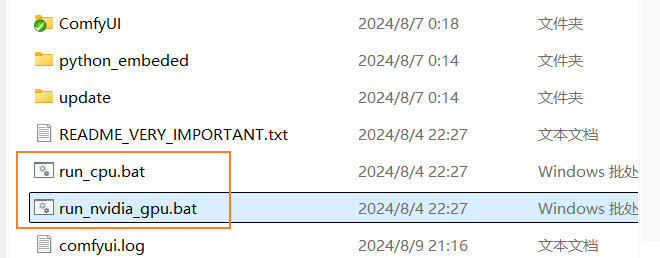
下载Stable Diffusion模型
1、Stable Diffusion XL Base 1.0:基础模型,https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/tree/main
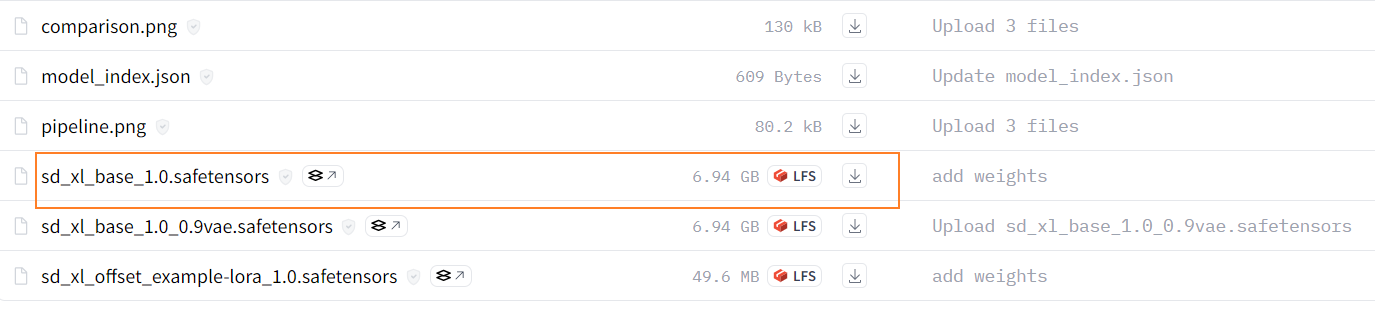
2、Stable Diffusion XL Refiner 1.0:https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0/tree/main
3、SDXL-VAE:https://huggingface.co/stabilityai/sdxl-vae/tree/main
上述三个模型下载完成后,分别放置到上面ComfyUI解压目录的如下目录:
- base、refiner以及后续其他模型:…\ComfyUI_windows_portable\ComfyUI\models\checkpoints
- vae:…\ComfyUI_windows_portable\ComfyUI\models\vae
界面说明
执行ComfyUI下面的run_nvida_gpu.bat,然后打开浏览器访问 http://127.0.0.1:8188/,界面如下:
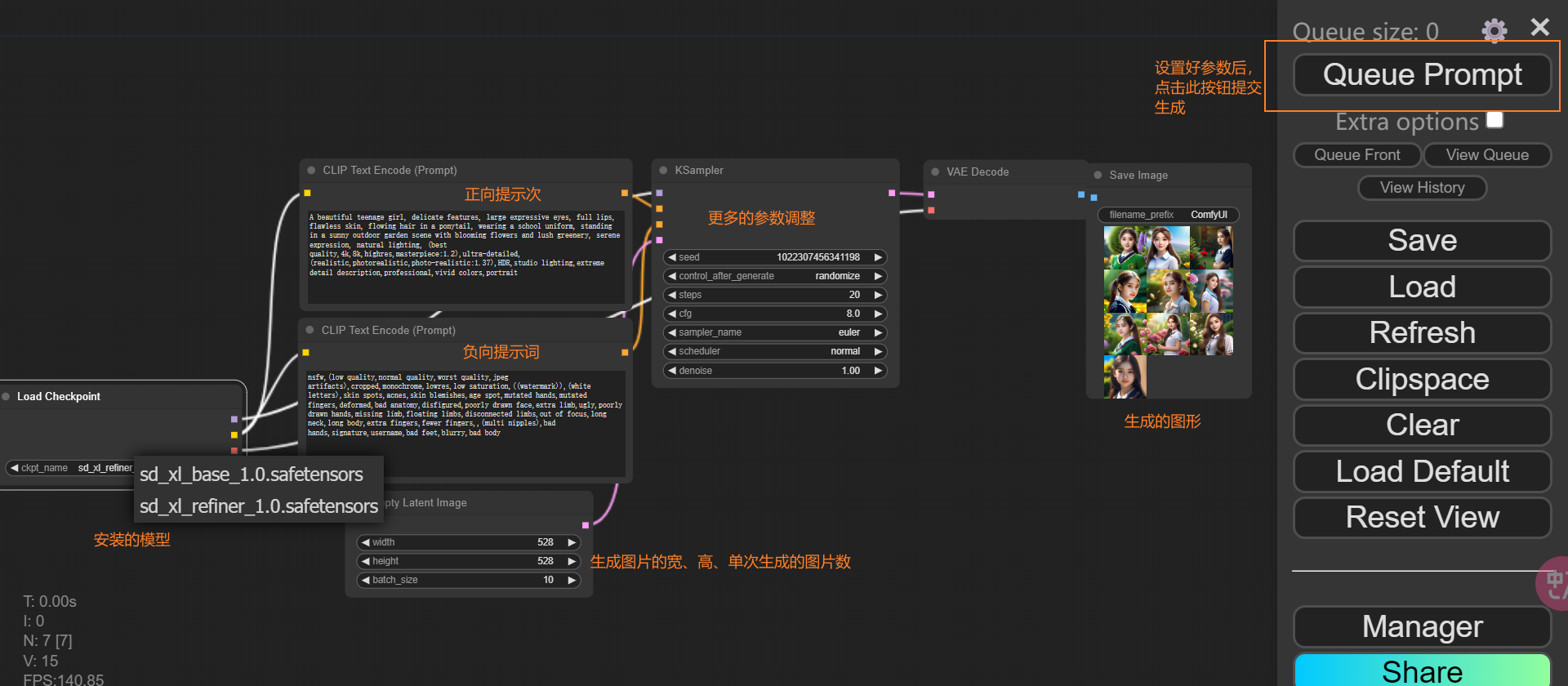
注意:执行过程中被绿色框起来的代表执行到了这一步。
ComfyUI Manager
Github网址:https://github.com/ltdrdata/ComfyUI-Manager
安装:在ComfyUI/custom_nodes目录下,执行 git clone https://github.com/ltdrdata/ComfyUI-Manager.git 并重启 ComfyUI
Stable Diffusion WebUI
安装
Stable Diffusion webUI
Github 仓库:https://github.com/AUTOMATIC1111/stable-diffusion-webui
Windows自动安装:
- 下载sd.webui.zip并解压:https://github.com/AUTOMATIC1111/stable-diffusion-webui/releases/download/v1.0.0-pre/sd.webui.zip
- 运行解压目录下的 update.bat
- 运行解压目录下的 run.bat
- 执行成功后,浏览器访问:http://127.0.0.1:7860
启动参数配置,在解压目录 webui\webui-user.bat 中添加如下参数,更多优化参数说明:https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Optimizations
# --autolaunch:Web UI 在启动后自动启动 Web 浏览器
# --update-check:在启动时检查 Web UI 的新版本
# --xformers:使用xFormers库,改善内存消耗和生成速度
set COMMANDLINE_ARGS=--autolaunch --update-check --xformers
运行碰到的问题:在浏览器打开 http://127.0.0.1:7860 时,在页面上任意交互操作都提示Something went wrong Expecting value: line 1 column 1 (char 0)
解决办法:关闭VPN工具或在 ...\webui\webui-user.bat 添加启动参数:--no-gradio-queue
模型资源下载网站
常用的绘画模型下载站:
- civitai:https://civitai.com/models
- Hugging Face:https://huggingface.co/
- 哩布哩布:https://www.liblib.art/
在线工具:
汉化
汉化插件:https://github.com/VinsonLaro/stable-diffusion-webui-chinese
安装方式:
-
打开stable diffusion webui,进入"Extensions"选项卡
-
点击"Install from URL",注意"URL for extension's git repository"下方的输入框
-
粘贴或输入Git仓库地址
https://github.com/VinsonLaro/stable-diffusion-webui-chinese -
点击下方的黄色按钮"Install"即可完成安装,然后重启WebUI(点击"Install from URL"左方的"Installed",然后点击黄色按钮"Apply and restart UI"网页下方的"Reload UI"完成重启)
-
点击"Settings",左侧点击"User interface"界面,在界面里最下方的"Localization (requires restart)",选择"Chinese-All"或者"Chinese-English"
-
点击界面最上方的黄色按钮"Apply settings",再点击右侧的"Reload UI"即可完成汉化
模型分类
- Checkpoint:Stable Diffusion绘图的基础模型,因此被称为大模型、底模型或者主模型。在WebUI上,它被称为Stable Diffusion模型。安装完Stable Diffusion软件后,必须搭配主模型才能使用。
- Checkpoint模型可以直接生成图像,而不需要额外的文件,一般为2GB~7GB
- Checkpoint模型主要有两种后缀名,safetensor和ckpt,存放在
webui\models\Stable-diffusion - 不同的模型库具有不同的风格,常见的风格有GhostMix(带科技感的2.5D风格)、Counterfeit(二次元卡通风格)、ChilloutMix(写实风格)
- LoRA:微调模型,可以固定某一类型的人物或者画面的风格。这些模型的文件大小通常为10 MB~200 MB,必须与Checkpoint模型一起使用,支持如下两种使用方式
- 在插件中使用,放在
webui\extensions - 在提示词中使用,放在
webui\models\lora
- 在插件中使用,放在
- LyCORIS模型:它可以让LoRA学习更多的层,可以看作升级的LoRA,归类为LoRA模型,属于微调模型的一种
- Controlnet模型:它是一种神经网络结构,通过添加额外的条件来控制扩散模型
- Textual Inversion模型(也称为Embedding):它是一种用于定义新关键词以生成新人物或图像风格的小文件,它也属于微调模型,用于个性化图像的生成。该模型的安装目录为
webui\models\Embedding - Hypernetwork模型:它是添加到Checkpoint模型中的附加网络模块,是个性化模型的一种。该模型的安装目录为
webui\models\hypernetworks - VAE模型:全称为Variational Autoencoder,中文叫变分自编码器。它的作用是滤镜+微调。大部分主模型训练时自带了VAE,它是一种美化模型,比如我们常用的ChilloutMix主模型,如果再加VAE美化模型可能图像效果会适得其反。如果我们生成的图像颜色不正常,就需要检查主模型配套的VAE模型
功能选项卡说明
Windows上安装CUDA
在Windows上安装CUDA:
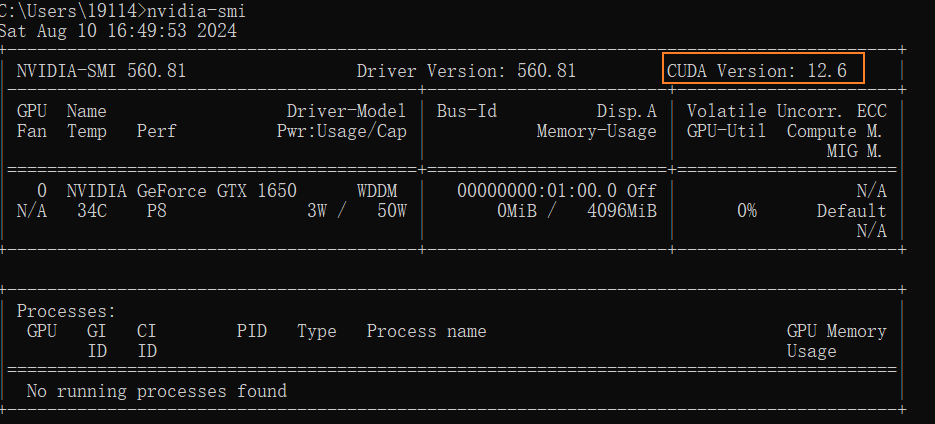
1、根据显卡型号更新显卡驱动:https://www.nvidia.cn/drivers/lookup/

2、在cmd窗口输入nvidia-smi,其中CUDA Version表示当前驱动支持的最新版本:
3、进入CUDA下载页面,下载小于等于上述显示版本的CUDA:https://developer.nvidia.com/cuda-toolkit-archive
并跟据操作系统和架构选择对应的安装包下载安装:
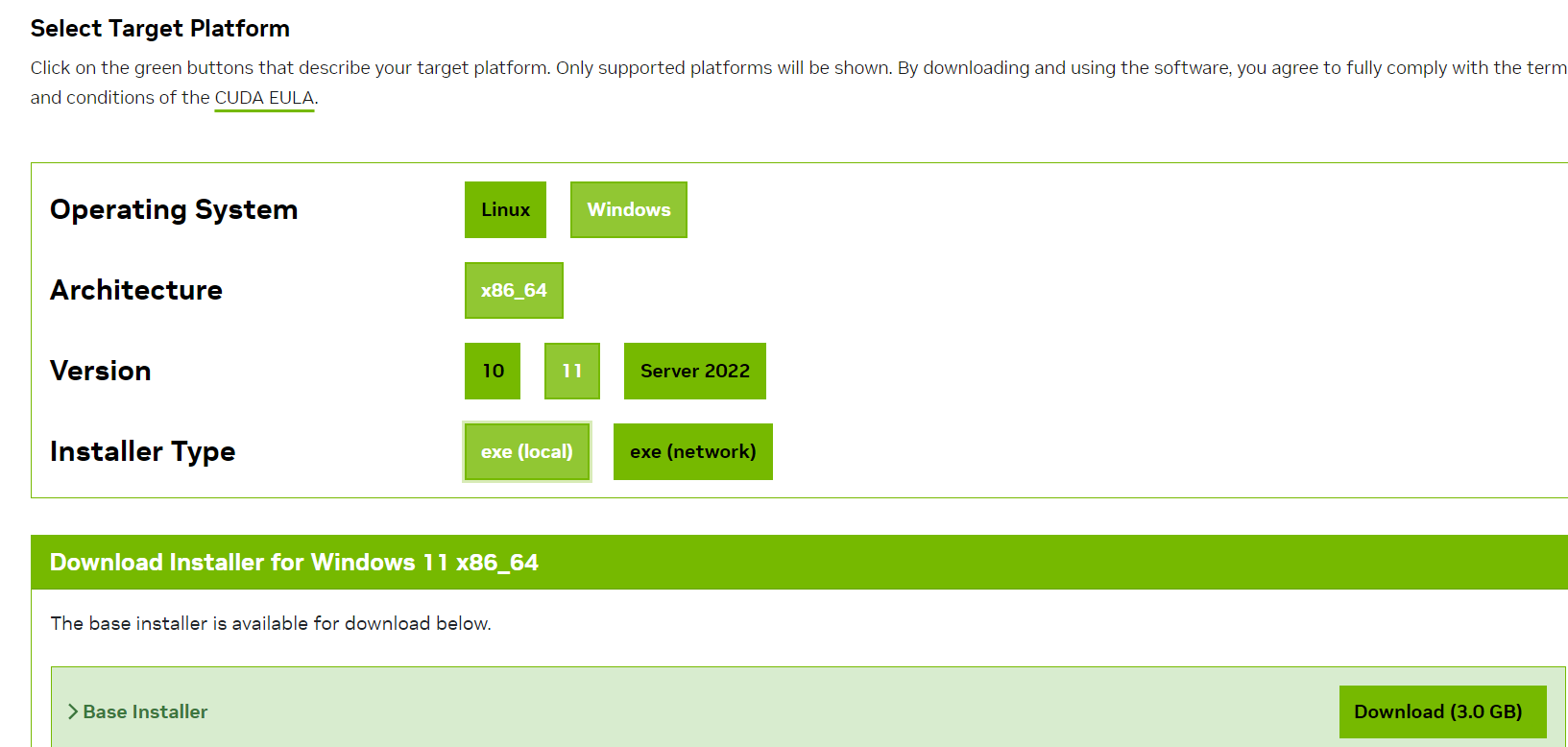
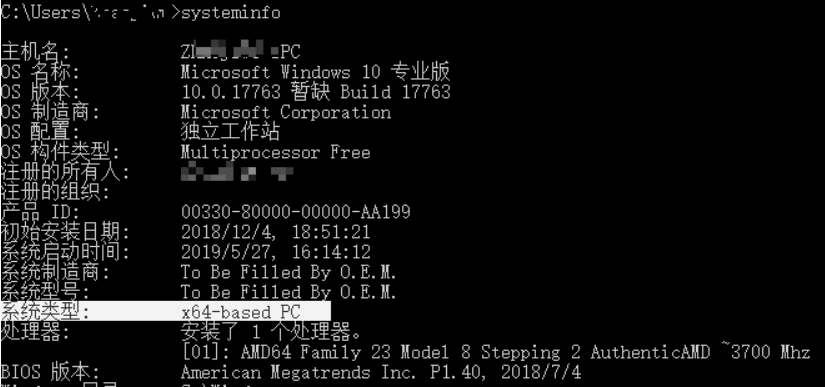
在cmd窗口输入systeminfo可以查看操作系统的架构:
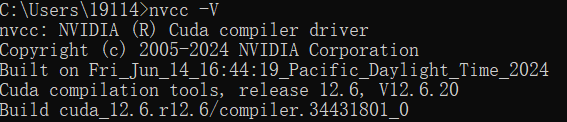
4、在cmd窗口输入nvcc -V,如果正常输出版本号则安装成功:
Stable Diffusion WebUI forge部署Flux模型
Stable Diffusion WebUI Forge下载
Stable Diffusion WebUI Forge Github网址:https://github.com/lllyasviel/stable-diffusion-webui-forge
下载:根据当前机器的CUDA版本,选择合适的安装包,此处选择推荐包
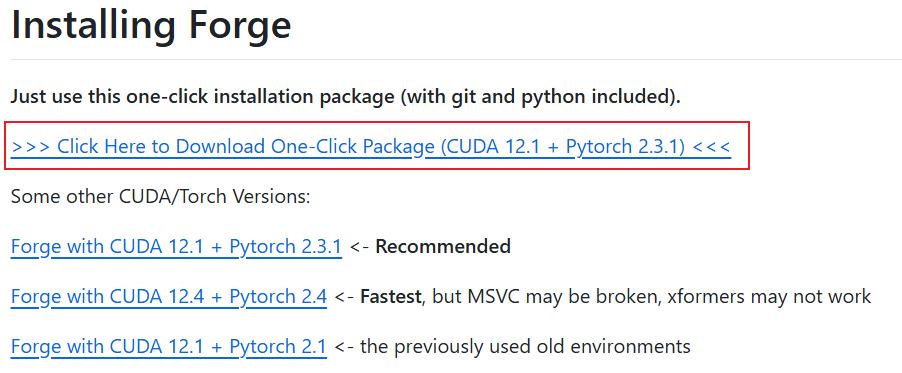
下载完成后,先执行update.bat脚本,再执行run.bat脚本。
Flux模型
参考:
Flux模型分类:
- Flux.1 pro:性能最强大,非开源仅支持API调用
- Flux.1 dev:性能较好,开源模型,非商业许可
- Flux.1 schnell:开源,在Apache2.0许可下商用
ComfyUI相关文件存放位置:
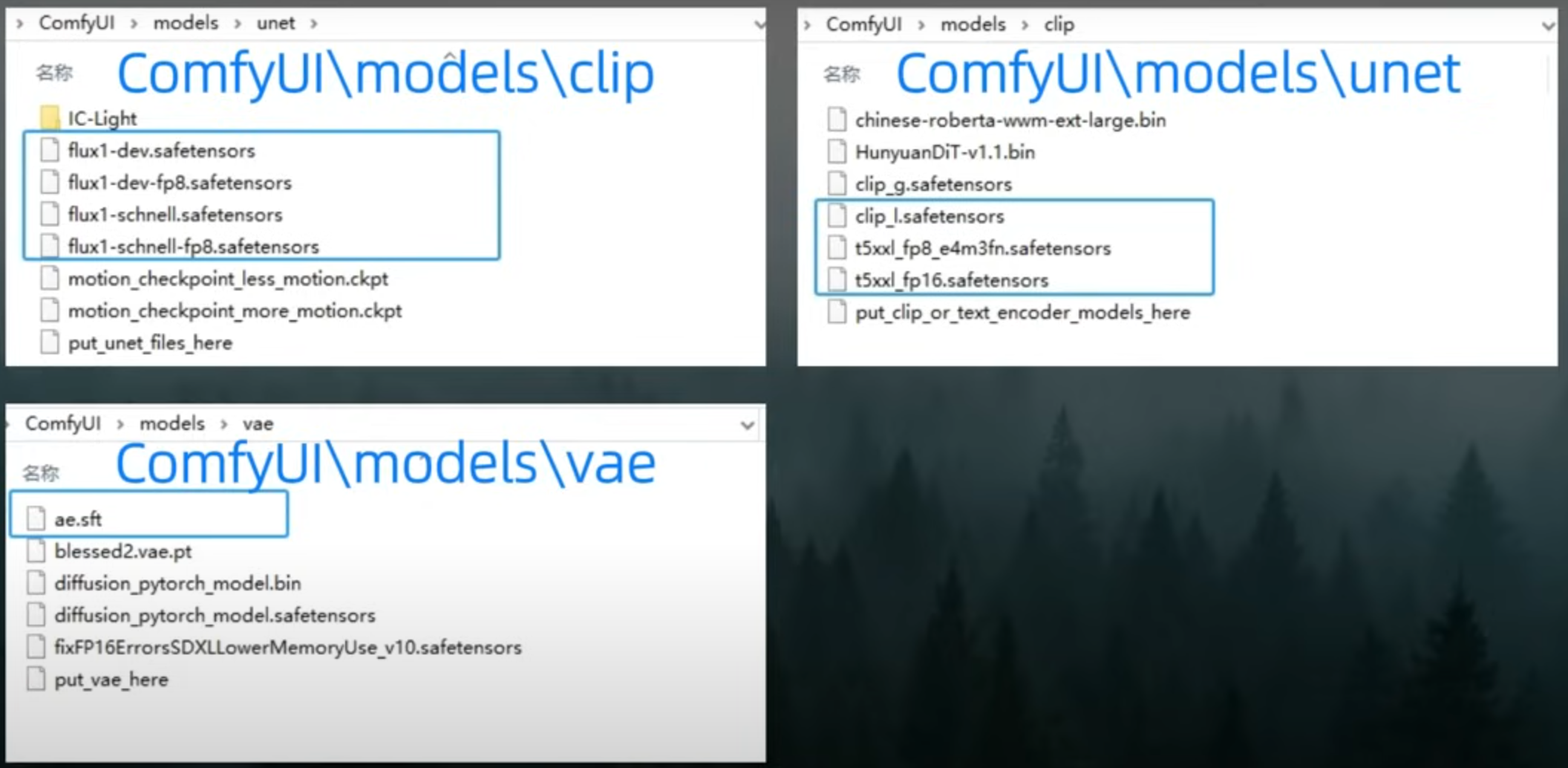
下载Flux官方FP16模型
Flux模型说明页面:https://github.com/lllyasviel/stable-diffusion-webui-forge/discussions/1050

1、下载基础模型和vae(负责从潜在空间解码生成像素空间的最终图像):
- 开发版:https://huggingface.co/black-forest-labs/FLUX.1-dev/tree/main
- 极速版:https://huggingface.co/black-forest-labs/FLUX.1-schnell
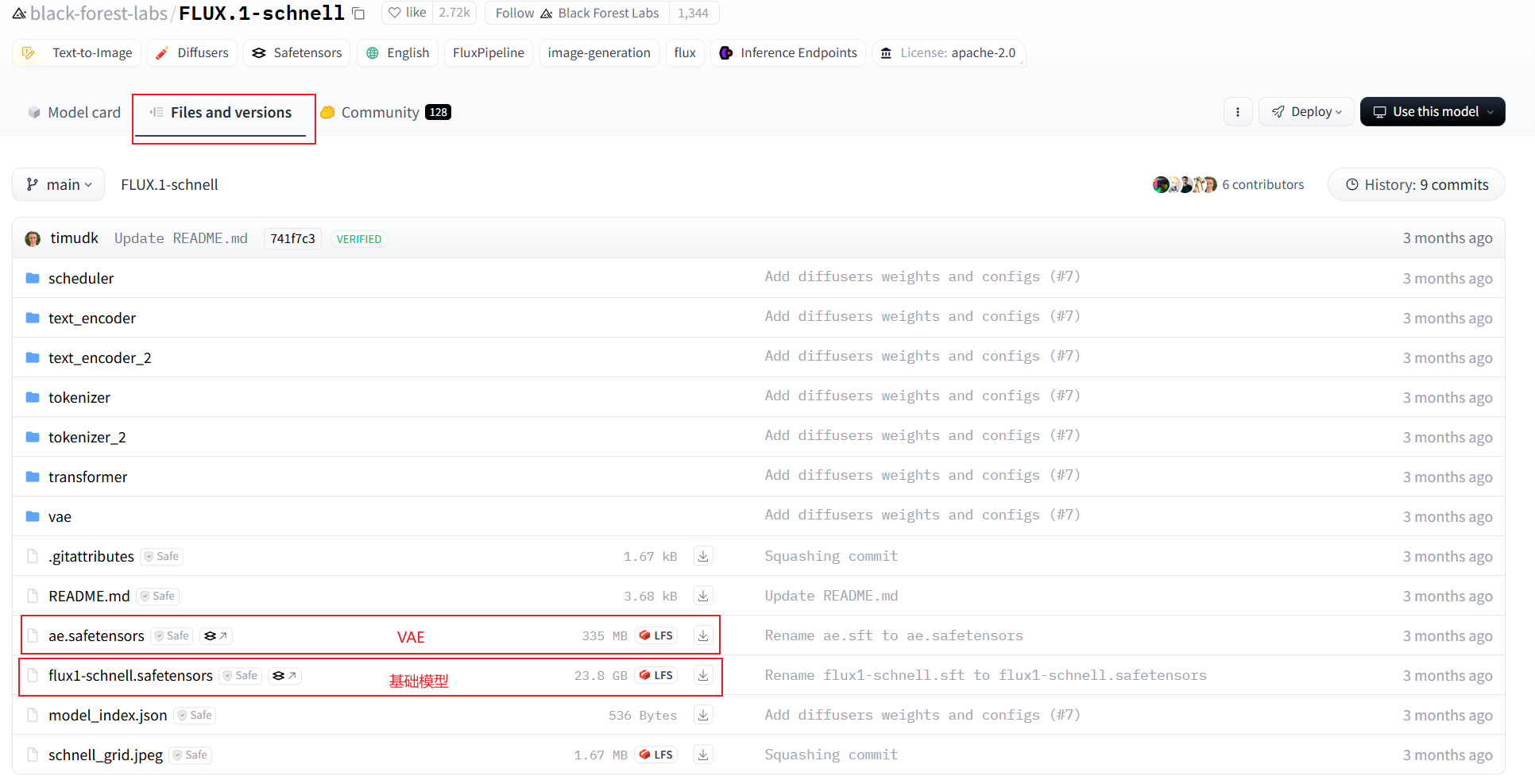
下载上图圈出来的两个文件,并放置到安装目录:
- flux1-schnell.safetensors 放到 models\Stable-diffusion 目录
- ae.safetensors 放到 models\VAE 目录
2、下载clip-l和t5:负责将文本提示转换成模型能理解的格式
- 原仓库地址:https://huggingface.co/comfyanonymous/flux_text_encoders/tree/main
- 镜像仓地址:https://huggingface.co/lllyasviel/flux_text_encoders/tree/main
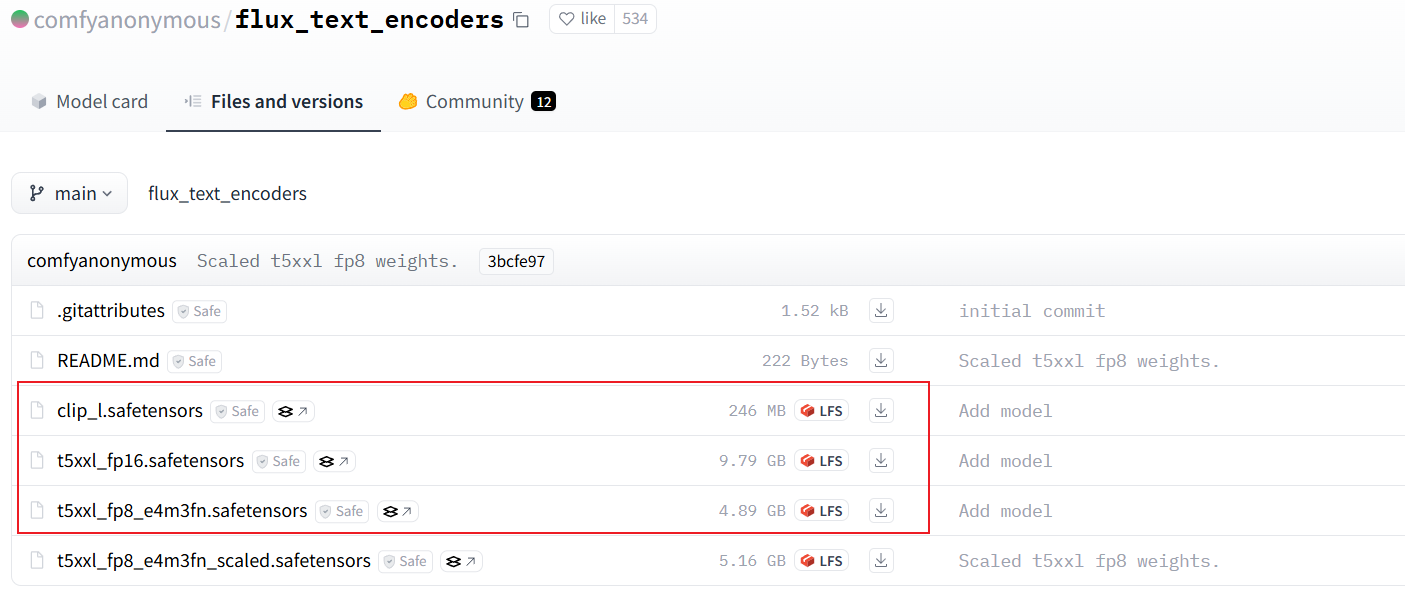
下载圈起来的三个文件,并全部放到 models\text_encoder 目录
下载精简FP8模型
Kijai版大模型
下载地址:https://huggingface.co/Kijai/flux-fp8/tree/main
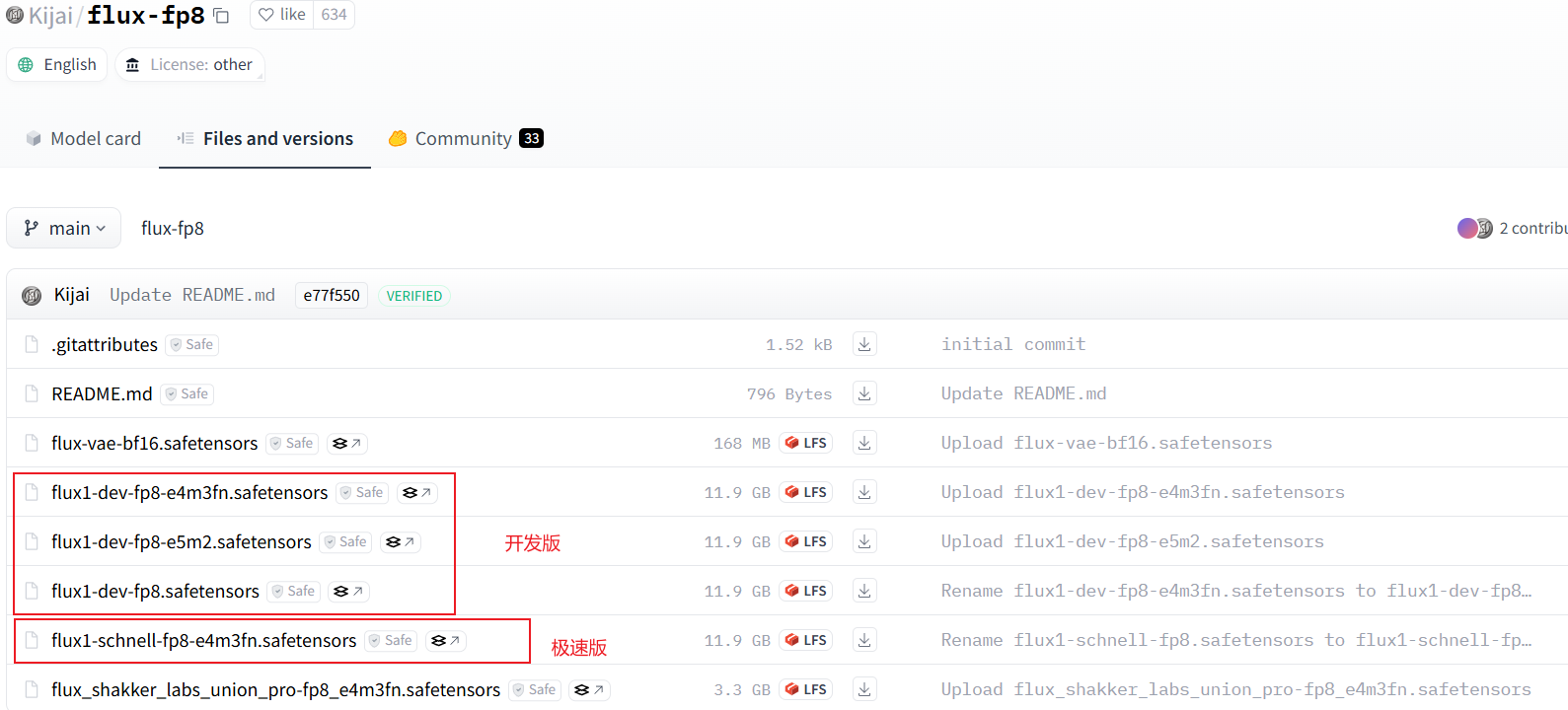
下载后放到 models\Stable-diffusion 目录
Comfy UI版
下载地址:https://huggingface.co/Comfy-Org/flux1-schnell/tree/main
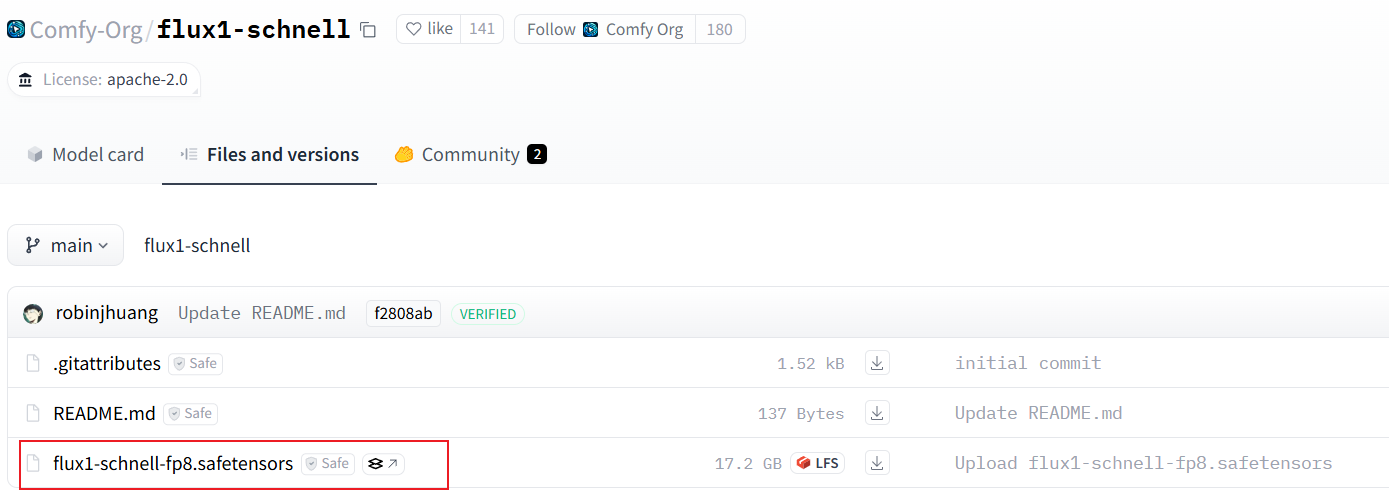
下载后放到 models\Stable-diffusion 目录
下载GGUF模型(适合显存较小的用户)
说明页:https://github.com/lllyasviel/stable-diffusion-webui-forge/discussions/1050

下载GGUF模型:
- 开发版:https://huggingface.co/lllyasviel/FLUX.1-dev-gguf
- 极速版:https://huggingface.co/lllyasviel/FLUX.1-schnell-gguf
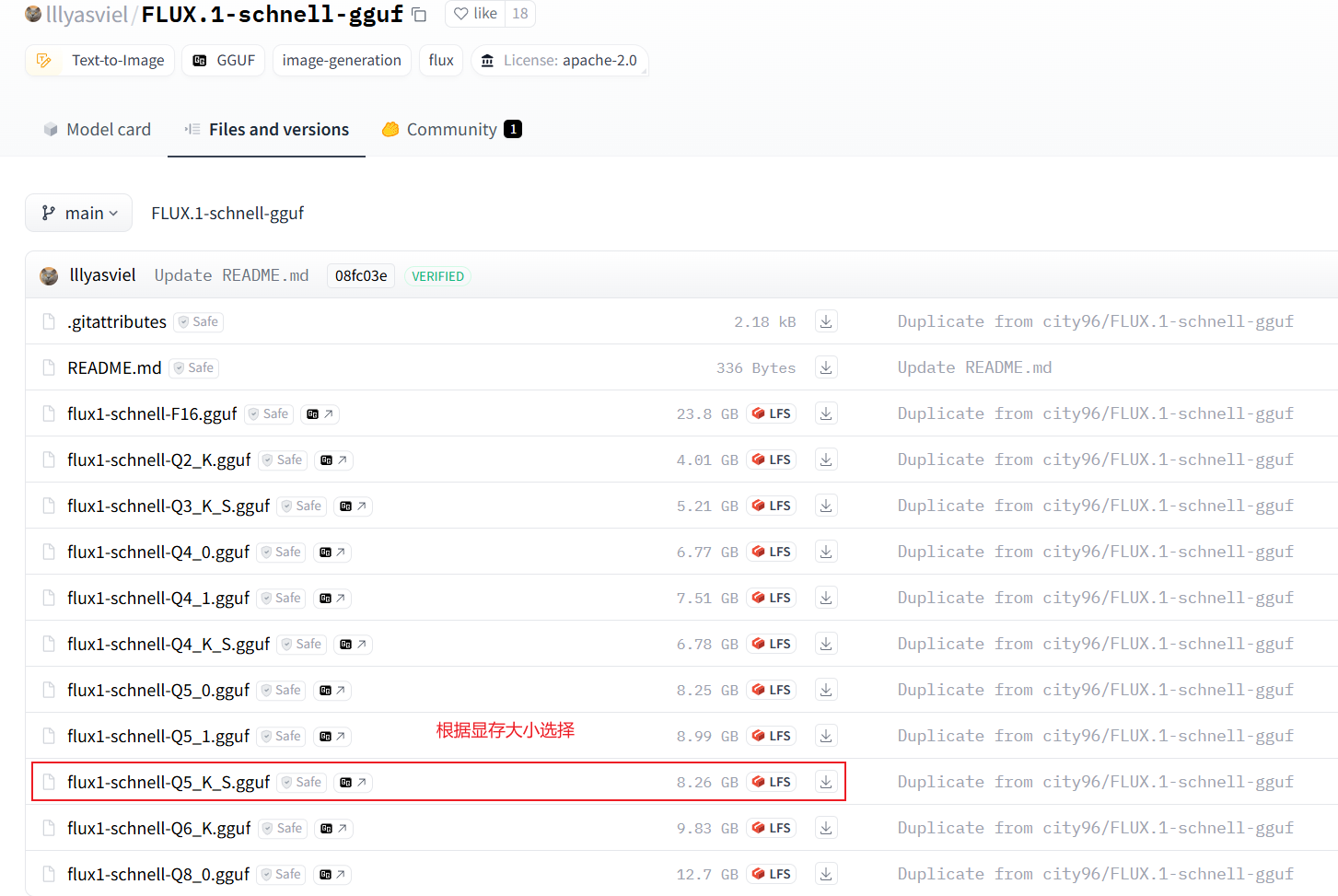
下载文件放在 models\Stable-diffusion 目录
下载NF4
说明页:https://github.com/lllyasviel/stable-diffusion-webui-forge/discussions/981
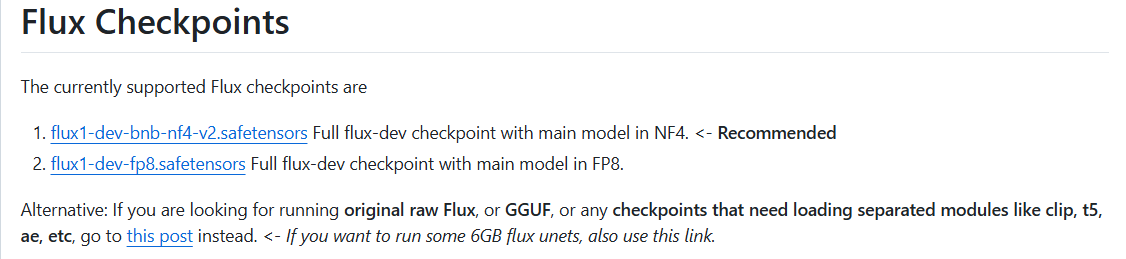
- 30、40系显卡:https://huggingface.co/lllyasviel/flux1-dev-bnb-nf4/blob/main/flux1-dev-bnb-nf4-v2.safetensors
- 其他显卡:https://huggingface.co/lllyasviel/flux1_dev/blob/main/flux1-dev-fp8.safetensors
下载完成后,放入 models\Stable-diffusion 目录
Flux模型使用说明
Flux1-SCHNELL、KIJAI、GGUF使用时需要配套开启clip和vae;而ComfyUI和NF4已经融合了clip和vae,可以直接出图。

Flux Guidance取值说明:
- 当值在1附近时,图像可能会显得灰暗
- 当值在2附近时,更适合生成艺术绘画风格的图像
- 当值在3到3.5时,能应对不同场景
- 当值超过3.5时,图像的细节可能会增强,但对比度可能也会很高
Flux推荐的采样器组合:
- ipdmn + simple
- uni_pc_bh2 + simple
- euler + beta
- euler + simple
- dpmpp + sgm_uniform
Flux模型常用提示词
常用提示词
特殊效果:https://www.maxbon.cn/archives/QdkQ7m4z
# 角色表情包
# 形象:写想生成的形象,如狗
# 形象描述:写形象的基本特征,如红头发白皮肤
An anime [形象], [形象描述],animated expression reference sheet, character design, reference sheet, turnaround, lofi style, soft colors, gentle natural linework, key art, range of emotions, happy sad mad scared nervous embarrassed confused neutral, hand drawn, award winning anime, fully clothed
# 全角度角色视图
# 形象:写想生成的形象,如狗
A character sheet of [形象] in different poses and angles, including front view, side view, and back view
# 双重曝光效果
# 内景:想生成的内景,比如森林
# 外景:写外景,比如狗狗
[内景] Inside a [外景]'s head, it's a double exposure photo. Non-figurative, colors and shapes, emotional expression, imaginative, highly detailed
# 照镜子效果
Cell phone photo of a dog taking a selfie in front of a mirror. The photo quality is grainy and details are slightly blurred. The lighting is dim and shadows obscure her features. [The room is messy, clothes are scattered on the bed, and the blanket is not laid out properly. Her expression is casual and focused], and the old iPhone has a hard time focusing, making the photo look real and unpolished. The mirror is covered with smudges and fingerprints, adding a raw, everyday vibe to the scene
图片风格
原网址:https://www.onetts.com/prompt/flux-prompt/106/
艺术风格:
- 印象派:impressionist, soft brushstrokes, light and color, natural scenes
- 立体主义:cubist, geometric shapes, multiple viewpoints, fragmented forms
- 超现实主义:surrealist, dreamlike, unexpected juxtapositions, bizarre imagery
- 波普艺术:pop art, bold colors, popular culture, graphic style
- 抽象表现主义:abstract expressionist, gestural brushstrokes, emotional intensity, large scale
- 点彩派:pointillism, dots, vibrant colors, optical mixing
- 新古典主义:neoclassical, idealized forms, symmetry, historical themes
- 未来主义:futurist, dynamic movement, technology, speed lines
绘画媒介:
- 油画:oil painting, thick textures, rich colors, visible brushwork
- 水彩:watercolor, translucent, fluid, delicate washes
- 素描:sketch, pencil, charcoal, monochrome, quick drawing
- 版画:printmaking, etching, linocut, woodcut, high contrast
- 丙烯:acrylic, bright, fast drying, versatile, smooth or textured
情感与氛围:
- 宁静:serene, calm, peaceful, soft lighting, gentle colors
- 激情:passionate, intense, dramatic, bold strokes, vivid colors
- 忧郁:melancholic, somber, muted tones, lonely, introspective
- 欢快:joyful, lively, bright, cheerful, energetic
特定元素:
- 光影效果:chiaroscuro, strong contrasts, dramatic lighting, shadows, highlights
- 纹理质感:texture, rough, smooth, grainy, tactile
- 色彩饱和度:saturation, vivid, pastel, desaturated, monochromatic
- 构图方式:composition, rule of thirds, symmetry, asymmetry, balance
rust入门
rust参考资料:
- Rust语言圣经:https://course.rs/
- Rust语言实战:https://practice-zh.course.rs/why-exercise.html
- Rust学习之旅:https://tourofrust.com/00_zh-cn.html
- 简单英语学rust:https://kumakichi.github.io/easy_rust_chs/Chapter_3.html
- Rust程序设计语言(英文版):https://doc.rust-lang.org/book/
- Rust程序设计语言(中文翻译):https://kaisery.github.io/trpl-zh-cn/title-page.html
- Rust程序设计语言:https://rustwiki.org/zh-CN/
- Rust标准库:https://rustwiki.org/zh-CN/std/index.html
- Cargo中文版手册:https://rustwiki.org/zh-CN/cargo/reference/overriding-dependencies.html
- Rust编程规范:https://rust-coding-guidelines.github.io/rust-coding-guidelines-zh/overview.html
环境搭建
Windows环境搭建
环境搭建:
1、配置rustup和cargo目录:
RUSTUP_HOME D:\rust\rustup_home
CARGO_HOME D:\rust\cargo_home
2、配置加速安装地址:
# 使用清华大学镜像源
RUSTUP_DIST_SERVER https://mirrors.tuna.tsinghua.edu.cn/rustup
RUSTUP_UPDATE_ROOT https://mirrors.tuna.tsinghua.edu.cn/rustup/rustup
# 或者指定其他的镜像源
# 字节跳动
RUSTUP_DIST_SERVER=https://rsproxy.cn
RUSTUP_UPDATE_ROOT=https://rsproxy.cn/rustup
# 中国科学技术大学
RUSTUP_DIST_SERVER=https://mirrors.ustc.edu.cn/rust-static
RUSTUP_UPDATE_ROOT=https://mirrors.ustc.edu.cn/rust-static/rustup
# 上海交通大学
RUSTUP_DIST_SERVER=https://mirrors.sjtug.sjtu.edu.cn/rust-static/
或者cmd设置临时环境变量:
SET RUSTUP_DIST_SERVER=https://mirrors.ustc.edu.cn/rust-static
3、配置cargo库镜像:在%homepath%\.cargo\或%CARGO_HOME%下创建config文件
[source.crates-io]
registry = “https://github.com/rust-lang/crates.io-index”
# 指定镜像
replace-with = ‘tuna’
# 中国科技大学
[source.ustc]
registry = "git://mirrors.ustc.edu.cn/crates.io-index"
# 清华大学
[source.tuna]
registry = "https://mirrors.tuna.tsinghua.edu.cn/git/crates.io-index.git"
# 上海交通大学
[source.sjtu]
registry = "https://mirrors.sjtug.sjtu.edu.cn/git/crates.io-index"
# rustcc社区
[source.rustcc]
registry = "https://code.aliyun.com/rustcc/crates.io-index.git"
4、下载安装程序后安装即可,支持两种工具链,选择msvc即可:https://www.rust-lang.org/zh-CN/
5、安装后检查:
rustc --version
cargo --version
6、打开本地文档服务:
rustup doc
7、Vscode安装rust开发插件:
- Rust原因插件:rust-analyzer
- TOML文件:Even Better TOML
- 错误展示:Error Lens
- Debugger程序:CodeLLDB
- 检查依赖更新检测:Dependi
8、VsCode设置:快捷键 Ctrl + , 打开设置
- 勾选:
Debug:Allow Breakpoints Everywhere - cargo check:将
Rust-analyzer › Check: Command设置为 clippy
9、卸载环境:
rustup self uninstall
项目创建
1、使用cargo创建项目:
cargo new hello
cd hello
code .
2、项目运行:
# 编译生成lib或可执行文件,支持release和debug模式
cargo build [--release|--debug]
# 检测代码是否能通过编译
cargo check
# 运行,等效于crago build && ./xx.exe
cargo run [--release|--debug]
mysql
视图
定义
视图本质上是一个虚拟表,它可以由数据库中的一张表或者多张表组合而成,视图从结构上也包含行和列。
- 可以对视图中的数据进行增加、删除、修改、查看等操作,也可以对视图的结构进行修改
- 在数据库中,视图不会保存数据,数据真正保存在数据表中。当对视图中的数据进行增加、删除和修改操作时,数据表中的数据会相应地发生变化;反之亦然。对视图的增删改查操作与操作普通表一致
应用场景
视图的应用场景:
- 数据安全:MySQL根据权限将用户对数据的访问限制在某些数据的结果集上,而这些数据的结果集可以使用视图来实现。因此,可以根据权限将用户对数据的访问限制在某些视图上,而不必直接查询或操作数据表,这在一定程度上保障了数据表中数据的安全性
- 数据独立:视图创建完成后,视图的结构就被确定了,当数据表的结构发生变化时不会影响视图的结构。当数据表的字段名称发生变化时,只需要简单地修改视图的查询语句即可,而不会影响用户对数据的查询操作
- 适应灵活多变的需求:当业务系统的需求发生变化后,如果需要改动数据表的结构,则工作量相对较大,可以使用视图来减少改动的工作量
- 能够分解复杂的查询逻辑:数据库中如果存在复杂的查询逻辑,则可以将问题进行分解,创建多个视图获取数据,再将创建的多个视图结合起来,完成复杂的查询逻辑
创建或修改视图
语法格式:
# 创建或更新视图
CREATE
[OR REPLACE]
[ALGORITHM = {UNDEFINED | MERGE | TEMPTABLE}]
[DEFINER = user]
[SQL SECURITY { DEFINER | INVOKER }]
VIEW view_name [(column_list)]
AS select_statement
[WITH [CASCADED | LOCAL] CHECK OPTION]
# 修改视图
ALTER
[ALGORITHM = {UNDEFINED | MERGE | TEMPTABLE}]
[DEFINER = user]
[SQL SECURITY { DEFINER | INVOKER }]
VIEW view_name [(column_list)]
AS select_statement
[WITH [CASCADED | LOCAL] CHECK OPTION]
语法格式说明:
- CREATE:新建视图
- REPLACE:替换已经存在的视图
- ALGORITHM:标识视图使用的算法
- UNDEFINED:MySQL自动选择算法
- MERGE:将引用视图的语句与视图定义进行合并
- TEMPTABLE:表示将视图的结果放置到临时表中,接下来使用临时表执行相应的SQL语句
- DEFINER:定义视图的用户
- SQL SECURITY:安全级别
- DEFINER:只有创建视图的用户才能访问视图
- NVOKER:具有相应权限的用户能够访问视图
- view_name:创建的视图名称
- column_list:视图中包含的字段名称列表
- select_statement:SELECT语句
- [WITH [CASCADED | LOCAL] CHECK OPTION]:保证在视图的权限范围内更新视图
示例:
CREATE TABLE users (
userid int primary key,
username varchar(50),
phonenum varchar(25),
address varchar(125)
);
CREATE TABLE salary (
salaryid int primary key,
count varchar(50),
userid int
);
insert users values (1, 'lisi', '18576485247', 'Shanghai'),(2, 'wangwu', '18576485256', 'Beijin');
insert salary values(1, '100', 1), (2, '200', 2);
# 默认情况下,创建的视图的字段名称和数据表的字段名称一样,也可以在创建视图时为视图指定字段名称
# create or replace:视图不存在时创建,视图存在时则更新
create or replace view view_users_salary (userid, username, count) as
select users.userid, users.username, salary.count from users join salary using (userid);
# 查看创建的视图
select * from view_users_salary;
# 使用alter更新视图
alter view users_salary (userid, username, phonenum, count) as
select users.userid, users.username, users.phonenum, salary.count from users join salary using (userid);
查看视图
查看视图:
# 查看当前数据库下的数据表和视图
# 注意:MySQL中不支持使用SHOW VIEWS语句查看视图
show tables;
# 查看视图的详细信息,主要是列信息
describe view_name;
desc view_name;
# 查看视图的统计信息
# Comment属性值为VIEW,说明查看的是视图
show table status like 'view_name';
# 查看视图的创建语句
SHOW CREATE VIEW 'view_name';
# MySQL会将视图信息存储到information_schema数据库下的views数据表
SELECT * FROM information_schema.views;
删除视图
删除视图:
DROP VIEW [IF EXISTS]
view_name [, view_name] ...
[RESTRICT | CASCADE]
存储过程和函数
MySQL从5.0版本开始支持存储过程和函数。存储过程和函数能够将复杂的SQL逻辑封装在一起,应用程序无须关注存储过程和函数内部复杂的SQL逻辑,而只需要简单地调用存储过程和函数即可。
应用场景
存储过程的应用场景:
- 具有良好的封装性:存储过程和函数将一系列的SQL语句进行封装,经过编译后保存到MySQL数据库中,可以供应用程序反复调用,而无须关注SQL逻辑的实现细节
- 应用程序与SQL逻辑分离:存储过程和函数中的SQL语句发生变动时,在一定程度上无须修改上层应用程序的业务逻辑,大大简化了应用程序开发和维护的复杂度
- 让SQL具备处理能力:存储过程和函数支持流程控制处理,能够增强SQL语句的灵活性,而且使用流程控制能够完成复杂的逻辑判断和相关的运算处理
- 减少网络交互:单独编写SQL语句在应用程序中处理业务逻辑时,需要通过SQL语句反复从数据库中查询数据并进行逻辑处理。每次查询数据时,都会在应用程序和数据库之间产生数据交互,增加了不必要的网络流量。使用存储过程和函数时,将SQL逻辑封装在一起并保存到数据库中,应用程序调用存储过程和函数,在应用程序和函数之间只需要产生一次数据交互即可,大大减少了不必要的网络带宽流
- 能够提高系统性能:由于存储过程和函数是经过编译后保存到MySQL数据库中的,首次执行存储过程和函数后,存储过程和函数会被保存到相关的内存区域中。反复调用存储过程和函数时,只需要从对应的内存区域中执行存储过程和函数即可,大大提高了系统处理业务的效率和性能
- 降低数据出错的概率:在实际的系统开发过程中,业务逻辑处理的步骤越多,出错的概率往往越大。存储过程和函数统一封装SQL逻辑,对外提供统一的调用入口,能够大大降低数据出错的概率
- 保证数据的一致性和完整性:通过降低数据出错的概率,能够保证数据的一致性和完整性
- 保证数据的安全性:在实际的系统开发过程中,需要对数据库划分严格的权限。部分人员不能直接访问数据表,但是可以为其赋予存储过程和函数的访问权限,使其通过存储过程和函数来操作数据表中的数据,从而提升数据库中数据的安全性
创建存储过程
创建存储过程语法:
CREATE PROCEDURE sp_name ([proc_parameter[,...]])
[characteristic ...] routine_body
参数格式说明:
- CREATE PROCEDURE:创建存储过程必须使用的关键字
- sp_name:创建存储过程时指定的存储过程名称
- proc_parameter:创建存储过程时指定的参数列表,参数列表可以省略
- characteristic:创建存储过程时指定的对存储过程的约束
- routine_body:存储过程的SQL执行体,使用BEGIN…END来封装存储过程需要执行的SQL语句
proc_parameter:在创建存储过程时指定的参数列表
[ IN | OUT | INOUT ] param_name type
参数格式说明:
- IN:当前参数为输入参数,也就是表示入参
- OUT:当前参数为输出参数,也就是表示出参
- INOUT:当前参数即可以为输入参数,也可以为输出参数,也就是即可以表示入参,也可以表示出参
- param_name:当前存储过程中参数的名称
- type:当前存储过程中参数的类型,此类型可以是MySQL数据库中支持的任意数据类型
characteristic:表示创建存储过程时指定的对存储过程的约束条件
LANGUAGE SQL
| [NOT] DETERMINISTIC
| { CONTAINS SQL | NO SQL | READS SQL DATA | MODIFIES SQL DATA }
| SQL SECURITY { DEFINER | INVOKER }
| COMMENT 'string'
参数格式说明:
- LANGUAGE SQL:存储过程的SQL执行体部分(存储过程语法格式中的routine_body部分)是由SQL语句组成的
- [NOT] DETERMINISTIC:执行当前存储过程后,得出的结果数据是否确定
- DETERMINISTIC:执行当前存储过程后得出的结果数据是确定的,即对于当前存储过程来说,每次输入相同的数据时,都会得到相同的输出结果
- NOT DETERMINISTIC:默认值。执行当前存储过程后,得出的结果数据是不确定的,即对于当前存储过程来说,每次输入相同的数据时,得出的输出结果可能不同
- {CONTAINS SQL | NO SQL | READS SQL DATA |MODIFIES SQL DATA}:存储过程中的子程序使用SQL语句的约束限制
- CONTAINS SQL:默认值。当前存储过程的子程序包含SQL语句,但是并不包含读写数据的SQL语句
- NO SQL:当前存储过程的子程序中不包含任何SQL语句
- READS SQL DATA:当前存储过程的子程序中包含读数据的SQL语句
- MODIFIES SQL DATA:当前存储过程的子程序中包含写数据的SQL语句
- SQL SECURITY {DEFINER | INVOKER}:执行当前存储过程的权限,即指明哪些用户能够执行当前存储过程
- DEFINER:默认值。只有当前存储过程的创建者或者定义者才能执行当前存储过程
- INVOKER:拥有当前存储过程的访问权限的用户能够执行当前存储过程
- COMMENT 'string':表示当前存储过程的注释信息,解释说明当前存储过程的含义
注意:在MySQL的存储过程中允许包含DDL的SQL语句,允许执行Commit(提交)操作,也允许执行Rollback(回滚)操作,但是不允许执行LOAD DATA INFILE语句。在当前存储过程中,可以调用其他存储过程或者函数。
示例:创建一个简单的存储过程
# 设置MySQL的语句结束符为$$
# MySQL默认的语句结束符为分号(;),如果不设置MySQL数据库的语句结束符,则存储过程中的SQL语句的结束符会与MySQL数据库默认的语句结束符相冲突
DELIMITER $$
# 创建存储过程:使用设置的语句结束符结束存储过程定义
CREATE PROCEDURE SelectAllData()
BEGIN
SELECT * FROM users;
END $$
# 恢复默认的语句结束符
DELIMITER ;
# 调用存储过程
call SelectAllData();
创建函数
创建函数的语法格式:
CREATE FUNCTION func_name ([func_parameter[,...]])
RETURNS type
[characteristic ...] routine_body
参数说明:
- CREATE FUNCTION:创建函数必须使用的关键字
- func_name:创建函数时指定的函数名称
- func_parameter:创建函数时指定的参数列表,参数列表可以省略
- RETURNS type:创建函数时指定的返回数据类型
- characteristic:创建函数时指定的对函数的约束
- routine_body:函数的SQL执行体
详细参数说明与存储过程一致,唯独存在如下区别:
- 存储过程的参数列表支持IN、OUT、INOUT类型
- 存储函数的参数列表仅支持IN类型,且不需要声明
示例:
# 定义函数
DELIMITER $$
CREATE FUNCTION FuncSelectById(id int)
RETURNS varchar(50)
READS SQL DATA
RETURN (SELECT username FROM users WHERE userid = id);
$$
DELIMITER ;
# 调用函数
SELECT FuncSelectById(1);
查看存储过程和函数
# 查看存储过程和函数的创建或定义信息
# sp_name:存储过程或函数名称
SHOW CREATE {PROCEDURE | FUNCTION} sp_name
# 查看存储过程和函数的状态信息
# [LIKE 'pattern']:匹配存储过程或函数名称,省略时查询所有存储过程或函数信息
SHOW {PROCEDURE | FUNCTION} STATUS [LIKE 'pattern']
# 从数据库中查看存储过程和函数的信息:information_schema.ROUTINES
# 精确查询
SELECT * FROM information_schema.ROUTINES where
ROUTINE_NAME = 'sp_name' [and ROUTINE_TYPE = {'PROCEDURE|FUNCTION'}];
# 模糊查询
SELECT * FROM information_schema.ROUTINES where
ROUTINE_NAME LIKE 'sp_name' [and ROUTINE_TYPE = {'PROCEDURE|FUNCTION'}];
修改存储过程和函数
创建存储过程和函数后,可以通过ALTER语句修改存储过程和函数的某些特性:
# 修改存储过程
# 修改时characteristic与创建时相比,不支持[NOT] DETERMINISTIC选项
ALTER PROCEDURE sp_name [characteristic ...]
# 修改函数,具体参数同创建时
ALTER FUNCTION func_name [characteristic ...]
调用存储过程和函数
# 调用存储过程
# CALL:调用存储过程的关键字
# proc_name:调用存储过程的名称
# parameter:存储过程定义的参数列表,当创建存储过程时没有定义参数列表,则参数列表为空
CALL proc_name ([parameter[,…]])
# IN变量:传入变量进入存储过程后如果参数被修改不会返回到用户的会话变量
set @id=1;
call selectById(@id); # 假如存储过程中修改了@id=2
select @id; # 此处仍然是1
# OUT或INOUT变量:必须传入局部变量,且修改会返回到用户的会话变量
set @name='';
call selectById(1, @name);
# 调用函数
# SELECT:调用函数的关键字,也是查询数据的关键字
# func_name:调用的函数名称
# parameter:调用函数的参数列表,当创建函数时没有定义参数列表,则参数列表为空
SELECT func_name ([parameter[,…]])
删除存储过程和函数
# 删除存储过程
# [IF EXISTS]:当需要删除的存储过程不存在时不会报错
DROP PROCEDURE [IF EXISTS] proc_name;
# 删除存储函数
DROP FUNCTION [IF EXISTS] func_name;
在MySQL中使用变量
MySQL中变量主要分为如下三种:
- 系统变量
- 用户变量
- 局部变量
系统变量分为全局变量和会话变量:
- 全局变量:启动时由服务器初始化,由配置文件my.ini或my.cnf配置,对全局变量修改影响整个MySQL服务
- 会话变量:建立新连接时初始化,默认会将当前所有全局变量的值复制一份作为会话变量,对会话变量修改仅影响当前会话
系统变量相关操作:
# 查看全局变量
show global variables;
# 查看具体的全局变量
elect @@gloabal.变量名;
# 修改全局变量的值
set gloabal 变量名 = ;
# 查看会话变量
show session variables;
# 查看某会话变量
select @@session.变量名;
# 修改会话变量值
set session 变量名 = ;
用户变量:当前会话连接有效
# 定义用户变量
SET @变量名;
SET @变量名 = '李四';
# 查询用户变量
SELECT @变量名;
局部变量:在MySQL数据库的存储过程和函数中,可以使用局部变量来存储查询或计算的中间结果数据,或者输出最终的结果数据。
局部变量定义:在MySQL数据库中,可以使用DECLARE语句定义一个局部变量,变量的作用域为BEGIN…END语句块,变量也可以被用在嵌套的语句块中。
- 变量的定义需要写在复合语句的开始位置,并且需要在任何其他语句的前面
- 定义变量时,可以一次声明多个相同类型的变量,也可以使用DEFAULT为变量赋予默认值
局部变量定义的语法格式:
DECLARE var_name[,...] type [DEFAULT value]
格式说明:
- DECLARE:定义变量使用的关键字
- var_name[,...]:定义的变量名称,可以一次声明多个相同类型的变量
- type:定义变量的数据类型,此类型可以是MySQL数据库中支持的任意数据类型
- [DEFAULT value]:定义变量的默认值,可以省略,如果没有为变量指定默认值,默认值为NULL
局部变量赋值:定义变量后,可以为变量进行赋值操作。变量可以直接赋值,也可以通过查询语句赋值。
# 使用SET语句为变量直接赋值
# SET:为变量赋值的关键字
# var_name:变量名称
# expr:变量的值,可以是一个常量,也可以是一个表达式
SET var_name = expr [, var_name = expr] ...
# 赋值示例
SET price = 29.99;
SET price = (29.99 * 1.5);
# 通过查询语句赋值:使用查询语句为变量赋值时,要求查询语句返回的结果数据必须只有一行
# table_expr:查询表数据时使用的查询条件,查询条件中包含表名称和WHERE语句
SELECT col_name[,...] INTO var_name[,...] table_expr
# 赋值示例
SELECT SUM(price) INTO totalprice FROM t_goods;
定义条件和处理程序
MySQL数据库支持定义条件和处理程序。
- 定义条件就是提前将程序执行过程中遇到的问题及对应的状态等信息定义出来,在程序执行过程中遇到问题时,可以返回提前定义好的条件信息
- 处理程序能够定义在程序执行过程中遇到问题时应该采取何种处理方式来保证程序能够继续执行
定义条件语法:
# condition_name:定义的条件名称
# condition_value:定义的条件类型
DECLARE condition_name CONDITION FOR condition_value
# condition_value取值:
# sqlstate_value:长度为5的字符串类型的错误信息
# mysql_error_code:数值类型的错误代码
SQLSTATE [VALUE] sqlstate_value | mysql_error_code
# 触发自定义条件
# 在异常处理部分可以使用RESIGNAL重新引发之前捕获的异常
SIGNAL condition_value | condition_name SET MESSAGE_TEXT = '自定义异常消息';
示例:
# 定义ERROR 2199(48000)错误条件,名称为exec_refused
# 使用sqlstate_value进行定义
DECLARE exec_refused CONDITION FOR SQLSTATE '48000';
# 使用mysql_error_code进行定义
DECLARE exec_refused CONDITION FOR 2199;
定义处理程序:
# handler_type:定义的错误处理方式
# condition_value:定义的错误类型
# sp_statement:当遇到定义的错误时,需要执行的存储过程或函数
DECLARE handler_type HANDLER FOR condition_value[,...] sp_statement
# handler_type取值:
# CONTINUE:遇到错误时,不进行处理,继续向后执行
# EXIT:遇到错误时,立刻退出程序
# UNDO:遇到错误时,撤回之前的操作。注意:目前MySQL数据库还不支持UNDO操作。
CONTINUE | EXIT | UNDO
# condition_value取值:
# STATE [VALUE] sqlstate_value:长度为5的字符串类型的错误信息
# condition_name:定义的条件名称
# SQLWARNING:所有以01开头的SQLSTATE错误代码
# NOT FOUND:所有以02开头的SQLSTATE错误代码
# SQLEXCEPTION:所有没有被SQLWARNING或NOT FOUND捕获的SQLSTATE错误代码
# mysql_error_code:数值类型的错误代码
SQLSTATE [VALUE] sqlstate_value
| condition_name
| SQLWARNING
| NOT FOUND
| SQLEXCEPTION
| mysql_error_code
示例:
# 定义处理程序捕获sqlstate_value值,当遇到sqlstate_value值为29011时,
# 执行CONTINUE操作,并且输出DATABASE NOT FOUND信息
DECLARE CONTINUE HANDLER FOR SQLSTATE '29011' SET @log=' DATABASE NOT FOUND';
# 定义处理程序捕获mysql_error_code的值,当遇到mysql_error_code的值为1162时,
# 执行CONTINUE操作,并且输出SEARCH FAILED信息
DECLARE CONTINUE HANDLER FOR 1162 SET @log=' SEARCH FAILED';
# 先定义search_failed条件,捕获mysql_error_code的值,
# 当遇到mysql_error_code的值为1162时,执行CONTINUE操作。
# 接下来定义处理程序,调用search_failed条件,并输出SEARCH FAILED信息
DECLARE search_failed CONDITION FOR 1162;
DECLARE CONTINUE HANDLER FOR search_failed SET @log=' SEARCH FAILED';
# 使用SQLWARNING捕获所有以01开头的sqlstate_value错误代码,
# 执行CONTINUE操作,并输出SQLWARNING信息
DECLARE CONTINUE HANDLER FOR SQLWARNING SET @log=' SQLWARNING';
# 使用NOT FOUND捕获所有以02开头的sqlstate_value错误代码,
# 执行EXIT操作,并输出SQL EXIT信息
DECLARE EXIT HANDLER FOR NOT FOUND SET @log=' SQL EXIT';
# 使用SQLEXCEPTION捕获所有没有被SQLWARNING或NOT FOUND
# 捕获的sqlstate_value错误代码,执行EXIT操作,并输出SQLEXCEPTION信息
DECLARE EXIT HANDLER FOR SQLEXCEPTION SET @log=' SQLEXCEPTION';
注意:带有@符号的变量(比如@log)是用户变量,可以使用SET语句进行赋值,用户变量与MySQL的连接有关。在一个客户端的连接会话中定义的用户变量,只能在此连接会话中可见并使用,当此连接会话关闭时,该连接会话中创建的所有变量都会被自动释放。
示例:自定义一个异常类型,并在存储过程中抛出处理
DROP PROCEDURE IF EXISTS funcTestProc;
DELIMITER $$
CREATE PROCEDURE funcTestProc()
BEGIN
DECLARE exec_refused CONDITION FOR SQLSTATE '48000';
# ERROR 1062 (23000): Duplicate entry '' for key 'PRIMARY'
# 处理主键冲突
DECLARE CONTINUE HANDLER FOR SQLSTATE '23000' SELECT 'Error, duplicate key occurred';
DECLARE CONTINUE HANDLER FOR exec_refused SELECT 'Error, exec_refused occurred';
INSERT INTO `users` (`userid`, `username`, `phonenum`, `address`) VALUES (1, 'lisi', '18576485247', 'Shanghai');
# 抛出自定义异常
SIGNAL exec_refused SET MESSAGE_TEXT='custom exception';
END $$
# 恢复默认的语句结束符
DELIMITER ;
# 调用存储过程
call funcTestProc();
示例:获取存储过程执行出错的原始信息,stackoverflow
# 适用于5.6.4之后的版本
CREATE PROCEDURE PROCNAME (
IN `ID` INT(11),
OUT `MESSAGE` VARCHAR(500),
OUT `Q_STATUS` BOOLEAN)
BEGIN
-- Error handling start here
DECLARE EXIT HANDLER FOR SQLEXCEPTION
BEGIN
GET DIAGNOSTICS CONDITION 1 @ERRNO = MYSQL_ERRNO, @MESSAGE_TEXT = MESSAGE_TEXT;
SET MESSAGE = CONCAT(@MESSAGE_TEXT, " : Erro code - ", @ERRNO);
SET Q_STATUS= 0;
ROLLBACK; -- if any error occures it will rollback changes
END;
-- main query start here
START TRANSACTION;
SELECT IAM, ID; -- THIS WILL CAUSE OF ERROR 'UNKNOWN COLUMN IAM'
SET Q_STATUS = 1; -- IF NO ERROR QUERY STATUS WILL GIVE YOU 1
COMMIT; -- it is necessary in transaction
END;
# 适用于5.6.4之前的版本
CREATE PROCEDURE procedure_name()
BEGIN
DECLARE EXIT HANDLER FOR SQLEXCEPTION
BEGIN
SHOW ERRORS; --this is the only one which you need
ROLLBACK;
END;
START TRANSACTION;
--query 1
--query 2
--query 3
COMMIT;
END
游标
游标:用于在存储过程和函数中循环处理结果集
# 声明游标
# cursor_name:声明的游标名称
# select_statement:SELECT查询语句的内容,返回一个创建游标结果数据的集合
DECLARE cursor_name CURSOR FOR select_statement
# 打开游标
OPEN cursor_name;
# 声明游标
# cursor_name:之前声明的游标名称
# var_name:接收创建游标时定义的查询语句的结果数据,可以定义多个var_name
# 注意:var_name必须在声明游标之前定义好。
FETCH cursor_name INTO var_name [, var_name] ...
# 关闭游标
CLOSE cursor_name;
示例:
DELIMITER //
CREATE PROCEDURE ProcessAllRows()
BEGIN
-- 声明游标
DECLARE done INT DEFAULT FALSE;
DECLARE example_data VARCHAR(255);
DECLARE cur CURSOR FOR SELECT column_name FROM your_table;
DECLARE CONTINUE HANDLER FOR NOT FOUND SET done = TRUE;
-- 打开游标
OPEN cur;
-- 循环遍历结果集
read_loop: LOOP
FETCH cur INTO example_data;
IF done THEN
LEAVE read_loop;
END IF;
-- 在这里处理每一行的数据
-- 例如,你可以打印数据或进行其他操作
SELECT example_data;
END LOOP;
-- 关闭游标
CLOSE cur;
END //
DELIMITER ;
控制流
MySQL数据库支持在存储过程或函数中使用IF语句、CASE语句、LOOP语句、LEAVE语句、ITERATE语句、REPEAT语句和WHILE语句进行流程的控制。
IF语句能够根据条件判断的结果为TRUE或者FALSE来执行相应的逻辑:
# 如果相应的search_condition条件为TRUE,则对应的statement_list语句将被执行;
# 否则执行ELSE语句对应的statement_list语句。
IF search_condition THEN statement_list
[ELSEIF search_condition THEN statement_list] ...
[ELSE statement_list]
END IF
CASE支持两种语法格式:
# case_value表示条件表达式,根据case_value的值,执行相应的WHEN语句。
# when_value为case_value可能的值,如果某个when_value的值与case_value的值相同,
# 则会执行当前when_value对应的THEN后面的statement_list语句;如果没有when_value的值与case_value的值相同,
# 则执行ELSE语句对应的statement_list语句。
CASE case_value
WHEN when_value THEN statement_list
[WHEN when_value THEN statement_list] ...
[ELSE statement_list]
END CASE
# search_condition为条件判断语句,当某个search_condition语句为TRUE时,执行对应的THEN后面的statement_list语句;
# 如果search_condition语句都为FALSE,则执行ELSE对应的statement_list语句
CASE
WHEN search_condition THEN statement_list
[WHEN search_condition THEN statement_list] ...
[ELSE statement_list]
END CASE
LOOP语句能够循环执行某些语句,而不进行条件判断,可以使用LEAVE语句退出LOOP循环:
# begin_label和end_label都是LOOP语句的标注名称,该参数可以省略。
# 如果begin_label和end_label两者都出现,则它们必须是相同的。
[begin_label:] LOOP
statement_list
END LOOP [end_label]
# LEAVE用于从被标注的流程结果中退出
# label:表示被标注的流程标志
LEAVE label
# ITERATE语句表示跳过本次循环,而执行下次循环操作,只可以出现在LOOP、REPEAT和WHILE语句内
# label:表示被标注的流程标志
ITERATE label
REPEAT语句会创建一个带有条件判断的循环语句,每次执行循环体时,都会对条件进行判断,如果条件判断为TRUE,则退出循环,否则继续执行循环体:
# begin_label和end_label为循环的标志,二者可以省略,如果二者同时出现,则必须相同。
# 当search_condition条件判断为TRUE时,退出循环
[begin_label:] REPEAT
statement_list
UNTIL search_condition
END REPEAT [end_label]
WHILE语句同样可以创建一个带有条件判断的循环语句。与REPEAT语句不同,WHILE语句的条件判断为TRUE时,继续执行循环体:
# begin_label和end_label为循环的标志,二者可以省略,如果二者同时出现,则必须相同。
# 当search_condition条件判断为TRUE时,继续执行循环体
[begin_label:] WHILE search_condition DO
statement_list
END WHILE [end_label]
动态SQL
在存储过程或函数中执行动态SQL,可以使用预处理语句:
# 获取预处理语句,预处理语句可以使用concat函数拼接,占位符使用问号?
PREPARE stmt_name FROM preparable_stmt;
# 执行预处理语句,可以使用用户变量
EXECUTE stmt_name [USING @var_name [, @var_name] ...];
# 释放预处理资源
{DEALLOCATE | DROP} PREPARE stmt_name;
示例:
SET @table_name := 'abc';
SET @value := '2023';
SET @sql_query := CONCAT('SELECT * FROM ', @table_name, ' WHERE column = ?');
PREPARE dynamic_statement FROM @sql_query;
EXECUTE dynamic_statement USING @value;
DEALLOCATE PREPARE dynamic_statement;
# 杀死特定用户连接
CREATE PROCEDURE kill_all_for_user(user_connection_id INT)
BEGIN
SET @sql_statement := CONCAT('KILL ', user_connection_id);
PREPARE dynamic_statement FROM @sql_statement;
EXECUTE dynamic_statement;
END;
触发器
MySQL从5.0.2版本开始支持触发器。MySQL中的触发器需要满足一定的条件才能执行,比如,在对某个数据表进行更新操作前首先需要验证数据的合法性,此时就可以使用触发器来执行。
创建
CREATE
[DEFINER = user]
TRIGGER trigger_name
trigger_time trigger_event
ON tbl_name FOR EACH ROW
[trigger_order]
trigger_body
语法格式:
- trigger_name:创建的触发器的名称
- trigger_time:标识什么时候执行触发器,支持两个选项,分别为BEFORE和AFTER
- BEFORE:表示在某个事件之前触发
- AFTER:表示在某个事件之后触发
- trigger_event:触发的事件,支持INSERT、UPDATE和DELETE操作
- tbl_name:数据表名称,表示在哪张数据表上创建触发器
- trigger_body:触发器中执行的SQL语句,可以有一条SQL语句,也可以是多条SQL语句
查看
# 查看触发器信息
# [{FROM | IN} db_name]:{FROM | IN}:表示从哪个数据库中查看触发器,db_name表示数据库名称,此项可以省略,当省略时,查看的是当前MySQL命令行所在的数据库的触发器信息
# [LIKE 'pattern' | WHERE expr]:查看触发器时匹配的条件语句
SHOW TRIGGERS
[{FROM | IN} db_name]
[LIKE 'pattern' | WHERE expr]
# 查看触发器的创建语句
SHOW CREATE TRIGGER trigger_name
# 从information_schema.triggers中获取触发器相关信息
SELECT * FROM information_schema.triggers WHERE condition
删除
# schema_name:触发器所在的数据库名称,当省略时,会删除MySQL命令行所在的数据库下的触发器
# trigger_name:触发器的名称
DROP TRIGGER [IF EXISTS] [schema_name.]trigger_name
分区
分区是指将一张表中的数据和索引分散存储到同一台计算机或不同计算机磁盘上的多个文件中。分区操作对于上层访问是透明的,用户访问MySQL中的分区表时,不必关心当前访问的数据存储到数据表的哪个分区中。对MySQL中的数据表进行分区也不会影响上层的业务逻辑。
查看是否支持分区操作
# 查看数据库是否支持分区操作
# MySQL 5.6以下版本
SHOW VARIABLES LIKE '%partition%';
# MySQL 5.7以上版本:partition显示ACTIVE
SHOW PLUGINS;
在MySQL 5.7及以下的版本中,支持使用大部分存储引擎创建分区表,例如可以使用MyISAM、InnoDB和Memory等存储引擎创建分区表,其他诸如MERGE、CSV等存储引擎不支持创建分区表。
在MySQL 5.1版本中,同一张数据表的所有分区必须使用同一个存储引擎,即一张数据表中不能对一个分区使用一种存储引擎,而对另一个分区使用其他存储引擎。
在MySQL 8.x版本中,MyISAM存储引擎已经不允许再创建分区表了,只能为实现了本地分区策略的存储引擎创建分区表,截至MySQL 8.0.18版本,只有InnoDB和NDB存储引擎支持创建分区表。
分区优势
分区表的优势:
- 存储更多的数据
- 优化查询:分区后,在WHERE条件语句中包含分区条件时,能够只扫描符合条件的一个或多个分区来查询数据,而不必扫描整个数据表中的数据,从而提高了数据查询的效率
- 并行处理:当查询语句中涉及SUM()、COUNT()、AVG()、MAX()和MIN()等聚合函数时,可以在每个分区上进行并行处理,再统计汇总每个分区得出的结果,从而得出最终的汇总结果数据,整体上提高了数据查询与统计的效率
- 快速删除数据:如果数据表中的数据已经过期,或者不需要再存储到数据表中,可以通过删除分区的方式快速删除数据表中的数据。删除分区比删除数据表中的数据在效率上要高得多
- 更大的数据吞吐量:分区后,能够跨多个磁盘分散数据查询,每个查询之间可以并行进行,能够获得更大的查询吞吐量,提升数据查询的性能
分区类型
在MySQL所有的分区类型中,进行分区的数据表可以不存在主键或者唯一键;如果存在主键或者唯一键,则不能使用主键或唯一键之外的其他字段进行分区操作。
MySQL的分区类型:
- RANGE分区:根据一个连续的区间范围,将数据分散存储于不同的分区,支持对字段名或表达式进行分区
- LIST分区:根据给定的值列表,将数据分散存储到不同的分区,支持对字段名或表达式进行分区
- HASH分区:根据给定的分区个数,结合一定的HASH算法,将数据分散存储到不同的分区,可以使用用户自定义的函数
- KEY分区:与HASH分区类似,但是只能使用MySQL自带的HASH函数
- COLUMNS分区:为解决MySQL 5.5版本之前RANGE分区和LIST分区只支持整数分区而在MySQL 5.5版本新引入的分区类型
- 子分区:对数据表中的每个分区再次进行分区
注意:RANGE分区与LIST分区有一定的相似性,RANGE分区是基于一个连续的区间范围分区,而LIST分区是基于一个给定的值列表进行分区;HASH分区与KEY分区类似,HASH分区既可以使用MySQL本身提供的HASH函数进行分区,也可以使用用户自定义的表达式分区,而KEY分区只能使用MySQL本身提供的函数进行分区。
RANGE分区
RANGE分区是根据连续不间断的取值范围进行分区,并且每个分区中的取值范围不能重叠,可以使用VALUES LESS THAN语句定义分区区间。
- 分区名称不区分大小写,即不能创建只有大小写不同的相同分区
CREATE TABLE t_members (
id INT NOT NULL,
first_name VARCHAR(30),
last_name VARCHAR(30),
join_date DATE NOT NULL DEFAULT '2020-01-01',
first_login_date DATE NOT NULL DEFAULT '2020-01-01',
group_code INT NOT NULL,
group_id INT NOT NULL
)
PARTITION BY RANGE (group_id)(
PARTITION part0 VALUES LESS THAN (10),
PARTITION part1 VALUES LESS THAN (20),
PARTITION part2 VALUES LESS THAN (30),
PARTITION part3 VALUES LESS THAN (40)
);
在MySQL中,可以通过查看information_schema数据库的partitions数据表来查看分区表的数据分布:
SELECT partition_name part, partition_expression expr,
partition_description part_desc, table_rows
FROM information_schema.partitions
WHERE table_schema = schema() AND table_name = 't_members';
在创建的分区表中,group_id字段的
win32编程
Windows程序分类:
- Console 控制台程序:入口函数main
- 窗口程序:入口函数WinMain
- 库程序:存放代码、数据的程序,执行文件可以从中取出代码执行和获取数据
- 静态库:扩展名 lib,在编译链接程序时,将代码放入到可执行文件,无入口函数
- 动态库:扩展名 dll,在执行文件执行时从中获取代码,入口函数DllMain
编译工具:
- 编译器:cl.exe,将源代码编译成目标代码,扩展名.obj
- 链接器:link.exe,将目标代码、库链接生成最终文件
- 资源编译器:rc.exe,将.rc资源编译,最终通过链接器存入最终文件
Windows库文件:C:\Windows\System32
- kernel32.dll:提供了核心的API,如进程、线程、内存管理等
- user32.dll:提供了窗口、消息等API
- gdi32.dll:绘图相关的API
头文件:
- windows.h:所有windows头文件的集合
- windef.h:windows数据类型
- winbase.h:kernel32的API
- wingdi.h:gdi32的API
- winuser.h:user32的API
- winnt.h:UNICODE字符集支持
相关函数:
int WINAPI WinMain(
HINSTANCE hInstance, // 当前程序的实例句柄
HINSTANCE hPrevInstance, // 当前程序前一个实例句柄
LPSTR lpCmdLine, // 命令行参数字符串
int nCmdShow // 窗口的显示方向
);
int MessageBox(
HWND hWnd, // 父窗口句柄
LPCTSTR lpText, // 显示在消息框中的文字
LPCTSTR lpCaption, // 显示在标题栏中的文字
UINT uType // 消息框中的按钮、图标显示类型
); // 返回点击的按钮ID
win32编译过程示例
示例:将下面内容保存为main.cpp
#include <windows.h>
int WINAPI WinMain(HINSTANCE hInstance, HINSTANCE hPrevInstance, LPSTR lpCmdLine, int nCmdShow) {
MessageBox(NULL, TEXT("hello world"), TEXT("EN"), MB_YESNOCANCEL|MB_ICONWARNING);
return 0;
}
通过https://convertio.co/zh转换获得一张ico文件,命名为main.ico,并创建main.rc:
100 ICON main.ico
在命令行进行编译链接生成一个带图标的应用程序:
# 加载编译环境,执行vcvars32.bat脚本
"C:\Program Files\Microsoft Visual Studio\2022\Community\VC\Auxiliary\Build\vcvars32.bat"
# 编译程序,生成main.obj
cl.exe -c main.cpp /utf-8
# 编译资源文件,生成main.res
rc.exe main.rc
# 链接程序,链接完成后生成可执行exe文件
link.exe main.obj user32.lib main.res
通过上面的示例,可以看出windows上的编译过程:
cl.exe
.c/.cpp -------------> .obj | link.exe
rc.exe | -------------> .exe
.rc -------------> .res |
字符编码
char、wchar_t与TCHAR:
-
char:每个字符占1个字节
-
wchar_t:unsigned short,每个字符占用2个字节,定义时需要增加L,用于通知编译器按照双字节编码字符串,采用UNICODE编码
// 需要使用支持wchar_t函数操作宽字节字符串 wchar_t* pwszText = L"Hello world"; wprintf(L"%s\n", pwszText); -
TCHAR:宏,根据是否定义UNICODE宏来处理字符串
void print() { TCHAR* cs = __TEXT("hello world"); #ifdef UNICODE wprintf(L"%s\n", cs); #else printf("%s\n", cs) #endif }
unicode字符打印:wprintf对unicode字符打印支持不完善,在Windows下使用WriteConsole API(GetStdHandle)印unicode字符
wchar_t* pszText = L"中文";
HANDLE hOut = GetStdHandle(STD_OUTPUT_HANDLE);
// 标准输出句柄,缓冲区,输出长度
WriteConsole(hOut, pszText, wcslen(pszText), NULL, NULL);
在Windows下,很多系统调用函数参数类型如下:
LPSTR == char* LPCSTR == const char*
LPWSTR == wchar_t* LPCWSTR == const wchar_t*
LPTSTR == TCHAR* LPCTSTR == const TCHAR*
使用VS开发时,可以在项目上右键,选择属性,进入属性页后,选择高级,将字符集由默认的“使用Unicode字符集”切换成“使用多字节字符集”,这样编译器不会自动定义UNICODE宏,从而在调用系统LPTSTR参数时,不需要传入宽字符。
win32窗口程序开发
win32窗口创建过程:
- 定义WinMain函数
- 定义窗口处理函数(自定义,处理数据)
- 注册窗口类(向操作系统写入一些数据)
- 创建窗口(内存中创建窗口)
- 显示窗口(绘制窗口的图像)
- 消息循环(获取/翻译/派发消息)
- 消息处理
安装wsl
官方文档:https://learn.microsoft.com/zh-cn/windows/wsl/install
# 安装发行版
wsl --install <Distribution Name>
# 列出可用的发行版
wsl --list --online
# 列出已安装的发行版
# --all:所有分发版
# --running:运行中的
# --quiet:仅显示发行版名称
wsl --list --verbose
# 设置默认的发行版
wsl --set-default <Distribution Name>
# 运行特定的发行版
wsl --distribution <Distribution Name> --user <User Name>
# 更新wsl
wsl --update
wsl2子系统重置密码
# Win + R 打开运行,输入cmd回车进入控制台
# 如果为默认分发版,使用如下分支进入根目录
wsl --user root
# 非默认分发版
wsl --list
wsl -d Debian -u root
# 修改root密码
passwd root
# 修改用户密码
passwd username
基础入门
UE5安装
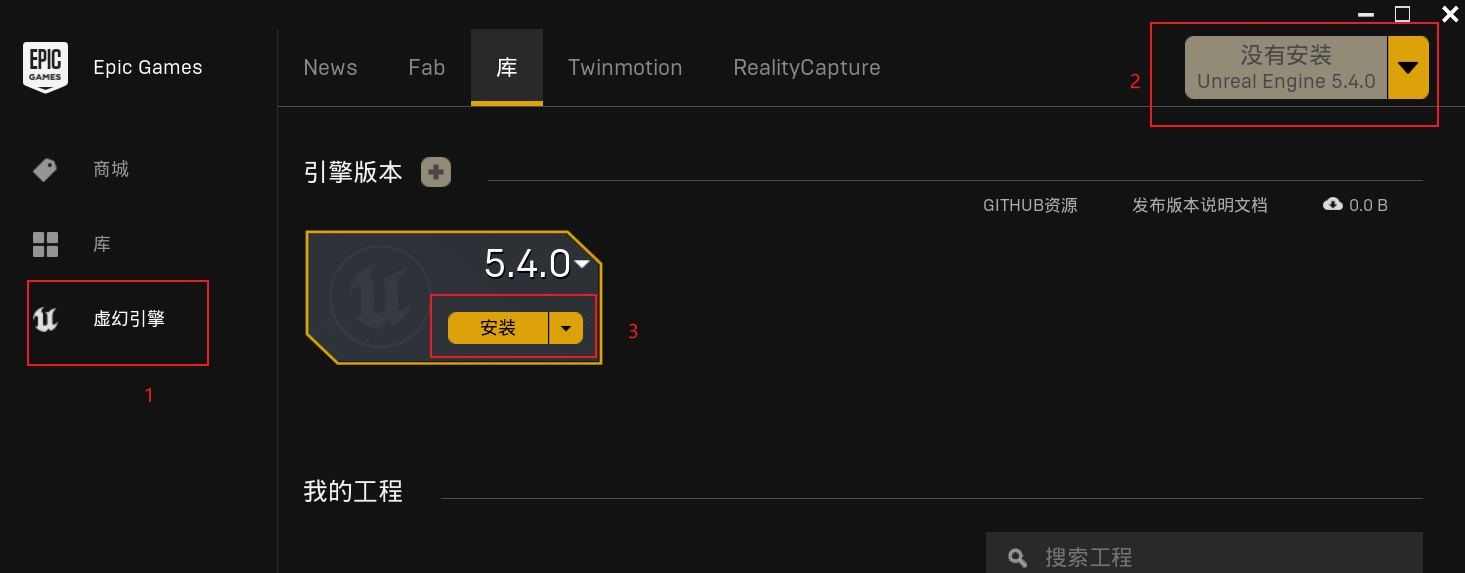
1、进入ue5官网并下载启动器:https://www.unrealengine.com/zh-CN/download
2、安装下载好的启动程序,注册账号并登录,登录后按照下图所示进行安装引擎(安装过程需要勾选协议并支持自定义安装位置):
项目创建
推荐配置:
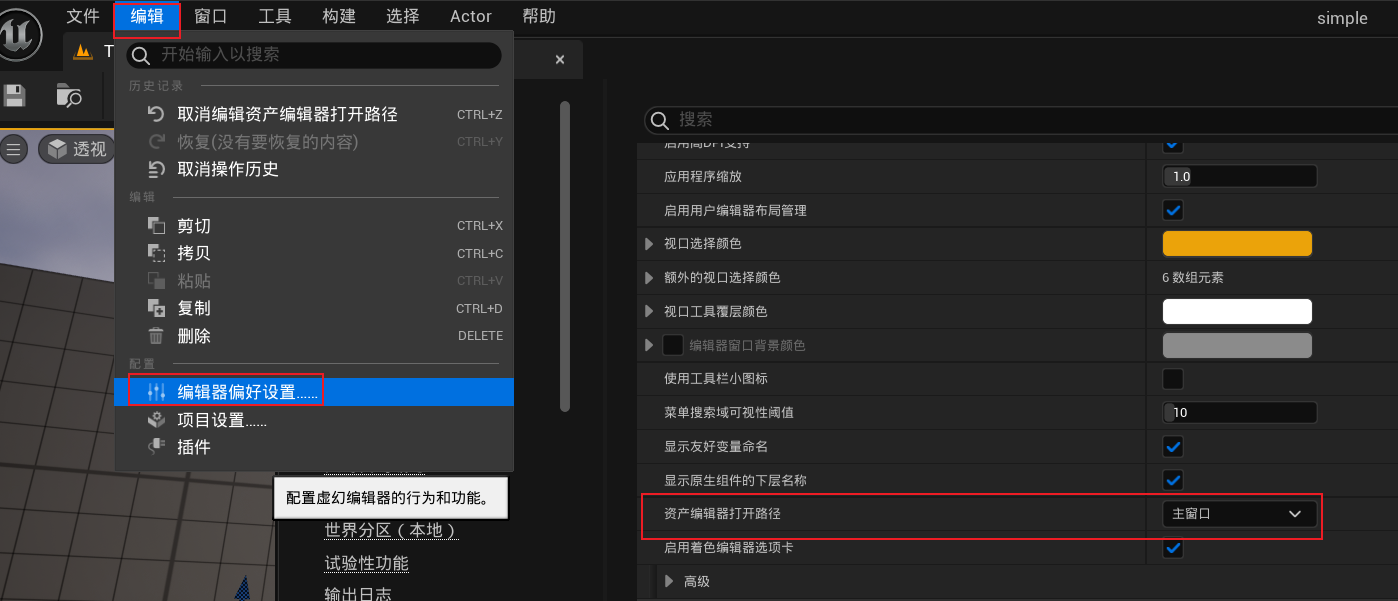
1、编辑 -> 编辑器偏好设置 -> 资产编辑器打开路径,切换为主窗口
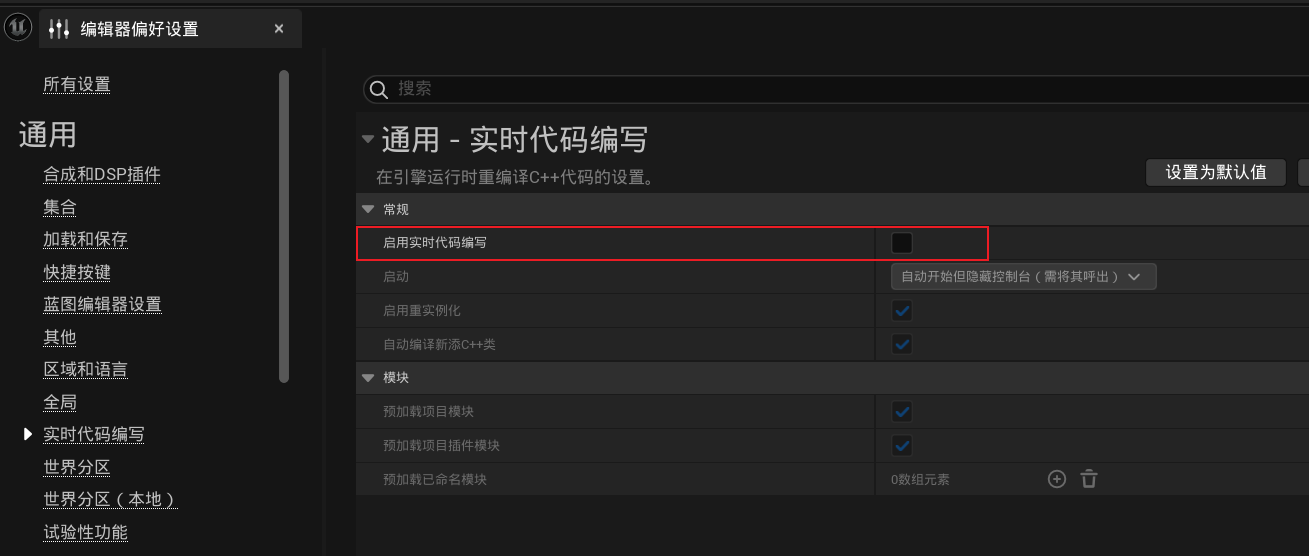
2、编辑 -> 编辑器偏好设置 -> 实时代码编写 -> 启用实时代码编写取消勾选
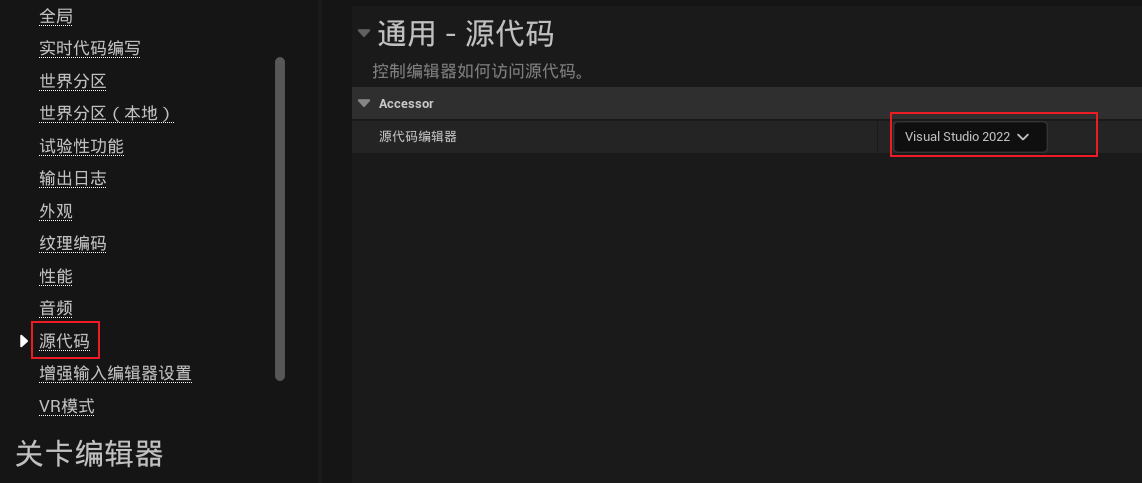
3、编辑 -> 编辑器偏好设置 -> 源代码 -> 源代码编辑器选择Visual Studio 2022:
以及Visual Studio 2022的组件:
4、如果时通过First Person或Third Person、Top Down等有默认的代码模板生成的项目,最好将头文件中的属性指针修改为TObjectPtr<T>